Який зв'язок між файловою системою та можливістю відновлення даних?
Почнемо з того, що будь-який пристрій зберігання даних, від крихітної карти пам'яті до громіздкого внутрішнього жорсткого диска, має один або кілька розділів. Це області на одному фізичному носії, що створюються операційною системою та розглядаються як окремі логічні диски. Інформація про них зазвичай зберігається на початку диска у так званій таблиці розділів.
Кожен розділ незалежний від інших і має власну файлову систему (скорочено ФС). Це основний механізм, який відповідає за розміщення даних у межах розділу. Завдяки ФС дані зберігаються у впорядкований спосіб та їх можна легко витягнути щоразу, коли у цьому є потреба.
Проте не всі файлові системи однакові: вони можуть мати різні принципи організації простору для зберігання даних. Окремі варіації здебільшого називають типами ФС або, рідше, форматами. Тип файлової системи може призначатися ОС автоматично, або ж остання може пропонувати користувачеві самостійно вибрати потрібний із наявних варіантів.
Кожен тип ФС відокремлює дані, що містяться у файлах, від інформації, що описує цей вміст, відомої як метадані. Останні включають назву файлу, його розмір, розташування, положення в структурі каталогів та інші властивості, які дозволяють його ідентифікувати. У той же час правила зберігання цих технічних деталей, яких дотримуються файлові системи, можуть суттєво відрізнятися.
Окрім регулювання способу розміщення інформації, файлова система також визначає спосіб її обробки під час видалення даних або форматування сховища. Як правило, вміст файлів не знищується одразу, тоді як метадані стираються або змінюються у такий спосіб, щоб системі було зрозуміло, що настав час їх позбутися. Таким чином, у разі будь-якої проблеми, через яку виникає потреба у відновленні даних, шанси на успішне повернення втраченого значною мірою залежать від поведінки застосованої ФС.
Якщо ви необачно видалили деякі дані або помилково відформатували увесь розділ, ви можете тверезо оцінити можливість виправити ситуацію, якщо знаєте тип файлової системи, яка виконала цю операцію. Тому давайте більш детально розглянемо різні формати Windows (NTFS, FAT/FAT32, exFAT, ReFS), macOS (HFS+, APFS), Linux (Ext2, Ext3, Ext4, ReiserFS, XFS, JFS) і BSD/Solaris/Unix (UFS, ZFS), їх загальну структуру, а також методи видалення даних та форматування.
Файлові системи Windows
Наразі Microsoft Windows пропонує два формати для внутрішніх дисків: NTFS і ReFS серверного рівня. Зовнішні запам'ятовувальні пристрої, такі як USB-накопичувачі та карти пам'яті, зазвичай використовують FAT/FAT32 або exFAT.
NTFS
На початку розділу NTFS розташований Завантажувальний запис тому (Volume Boot Record або VBR). Цей файл містить інформацію про розмір і структуру файлової системи, а також код завантаження.
NTFS керує даними за допомогою Головної файлової таблиці (Master File Table або MFT). По суті, це база даних, що містить записи для кожного файлу та папки у ФС. Кожен запис у таблиці MFT містить різноманітні атрибути, як-от місце розташування, ім'я, розмір, дата/час створення та останніх змін. Сама Головна файлова таблиця має атрибут Bitmap, який вказує на те, які із записів зараз використовуються.
Дуже маленькі файли зберігаються як атрибути безпосередньо в комірці таблиці MFT. Якщо ж файл великий, він зберігається за межами MFT, яка натомість містить запис, що вказує на його розташування. Аналогічним чином, коли атрибути не вміщуються в один запис MFT, вони виносяться за межі таблиці, у якій зберігаються лише їхні адреси.
Папки в NTFS представлені записами каталогу. Це файли, які містять списки інших файлів із посиланнями на них.
Іншим важливим для NTFS файлом є Бітова мапа (Bitmap). У ній ведеться облік всіх зайнятих та вільних місць у файловій системі.
На малюнку нижче ви можете побачити взаємозв'язки між ключовими елементами структури NTFS – Завантажувальним записом тому ($Boot), Головною файловою таблицею ($MFT) і областю зберігання даних:

Видалення
Процедура: NTFS зберігає запис MFT для цього файлу, але із позначкою "невикористаний", а місце, зайняте його вмістом, позначає в Bitmap як звільнене. Файл також видаляється із запису каталогу.
Відновлення: Ім'я, розмір і розташування файлу мають залишитись у відповідному записі у таблиці MFT. Якщо цей запис залишився без змін і вміст файлу ще не було перезаписано, шанси відновити останній становлять 100%. Якщо ж цей запис відсутній, може статися, що файл все ще можна знайти в обхід структури ФС за допомогою методу RAW-відновлення. У цьому разі необроблені дані на диску аналізуються на наявність попередньо визначених шаблонів, які характеризують файли даного типу. Однак головним недоліком цього підходу є відновлення файлів без оригінальних назв і папок.
Форматування
Процедура: Система створює нову Головну файлову таблицю, яка стирає початок існуючої. Однак решта таблиці залишається як є.
Відновлення: Перші 256 файлів більше не представлені у таблиці MFT, тому їх відновлення можливе лише за допомогою методу RAW-відновлення. Шанси на відновлення файлів, що зберігалися після вищезгаданих 256, становлять аж до 100%.
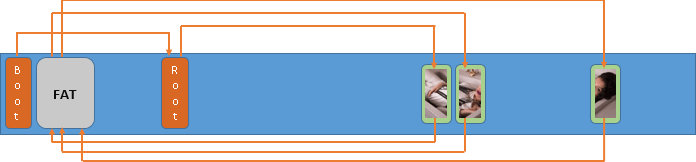
FAT/FAT32
Основна інформація про організацію файлової системи доступна в Завантажувальному секторі (Boot Sector) на самому початку розділу.
FAT/FAT32 розділяє простір для зберігання даних на частини однакового розміру, які називаються кластерами. Вміст файлу може займати один або кілька кластерів, які не обов'язково розташовані близько один до одного. Файли, вміст яких зберігається не у послідовно розташованих кластерах, називаються фрагментованими.
Таблиця розміщення файлів (File Allocation Table або FAT) відстежує, які кластери зайняті якими файлами. З метою резервного копіювання у системі зазвичай зберігаються дві копії цієї таблиці. Кожен кластер має власний запис у Таблиці розміщення файлів, у якому вказується, чи він зайнятий. Якщо так, у ньому також міститиметься посилання на наступний кластер, що належить тому самому файлу, або позначка про те, що це останній кластер у ланцюжку.
Кореневий каталог (Root Directory) — це низка записів, які описують усі файли та папки. Кожен запис каталогу містить початковий кластер файлу, а також його назву, розмір та інші атрибути. Номер цього кластера також вказує на запис у таблиці FAT.
На малюнку нижче ви можете побачити, як пов'язані між собою ключові елементи структури FAT/FAT32 – Завантажувальний сектор, дві Таблиці розміщення файлів FAT, Кореневий каталог і область зберігання даних:

Видалення
Процедура: FAT/FAT32 позначає запис каталогу файлу як видалений і прибирає всю інформацію, що міститься у відповідних записах таблиці FAT, знищуючи, таким чином, посилання на його проміжні та кінцевий кластери. Перший символ у назві файлу замінюється значенням, що вказує на його видалений стан. FAT32 також частково видаляє інформацію про початковий кластер файлу.
Відновлення: Перший кластер і розмір файлу все ще можна знайти в записі каталогу, тоді як розташування проміжних і кінцевого кластерів можна лише припустити. З цієї причини результати відновлення даних можуть бути неповними. Крім того, FAT/FAT32 не виконує дефрагментацію, що ускладнює відновлення файлів за допомогою методу RAW-відновлення. Інша проблема полягає в тому, що імена файлів обмежені у довжині і навіть можуть зберігатися відокремлено на сховищі. Отже, відновлення довгих імен може не мати успіху.
Форматування
Процедура: Обидві копії Таблиці розміщення файлів очищаються, а Кореневий каталог видаляється. Проте вміст файлів все ще зберігається.
Відновлення: Як і за попереднього сценарію, файли, збережені у послідовно розміщених кластерах, можна відновити за допомогою методу відновлення RAW (за відомим вмістом). Проте через фрагментацію значна частина даних може виявитися пошкодженою.
exFAT
exFAT була розроблена як наступниця FAT/FAT32, тому вона дуже схожа на інші файлові системи цього сімейства. Структура тому exFAT також описується в Завантажувальному секторі (Boot Sector). Задля безпеки система зберігає ще одну копію Завантажувального сектора.
exFAT також застосовує Таблицю розміщення файлів (File Allocation Table або FAT), однак у цій ФС є лише одна її копія і вона містить посилання лише для фрагментованих файлів. Крім того, статус кластеру вказаний не безпосередньо в записі, а у спеціальній Бітовій мапі розподілу (Allocation Bitmap). Ця мапа зберігається в області зберігання даних і показує, чи кластер вже зайнятий, чи готовий до запису. Такий підхід полегшує exFAT пошук суміжних кластерів для розміщення вмісту файлу, а отже, усуває фрагментацію.
Записи каталогу обробляються так само, як у FAT/FAT32, але в Кореневому каталозі (Root Directory) на додаток є спеціальний запис з інформацію про Бітову мапу розподілу.
На малюнку нижче ви можете побачити взаємозв'язки між ключовими елементами структури exFAT – Завантажувальним сектором, Таблицею розміщення файлів FAT, Кореневим каталогом і областю зберігання даних:
Видалення/форматування
Процедура: exFAT змінює стан відповідних кластерів у файлі Бітової мапи розподілу. Записи у таблиці FAT не оновлюються одразу, щоб уникнути непотрібних операцій запису. Область зберігання даних також не очищується.
Відновлення: Якщо файл фрагментований, ланцюжок його кластерів можна відновити за допомогою тих записів у FAT, що залишилися. Якщо посилання на ці кластери втрачені, відновлення може бути неповним. Тим не менш, метод відновлення за відомим вмістом може принести доволі непогані результати, завдяки меншому рівню фрагментації у exFAT порівняно з FAT/FAT32.
ReFS
Дизайн ReFS значно відрізняється від решти форматів Microsoft Windows. Інформація у цій файловій системі зазвичай організована у вигляді B+-дерев, які працюють подібно до баз даних. B+-дерева використовуються майже для всіх елементів файлової системи, включно з вмістом файлів і метаданими. Таке дерево складається з кореня, внутрішніх вузлів і листя. Кожен вузол дерева має впорядкований список ключів і вказівники на вузли нижчого рівня або листя.
Каталог (Directory) є основним компонентом цієї ФС. Він також представлений у вигляді B+-дерева. Ключ в ньому відповідає номеру об'єкта-папки. Файл не розглядається як окремий елемент Каталогу і існує у формі запису.
Іншою помітною особливістю ReFS є використання Копіювання при записуванні (англ. Copy-on-Write (CoW)): оригінальні записи файлової системи ніколи не змінюються одразу, а просто копіюються, а потім записуються до нового місця разом із усіма застосованими змінами.
Видалення
Процедура: Структура метаданих має бути перебудована у відповідь на видалення файлу. Однак ReFS не редагує метадані прямо на місці. Замість цього вона створює їх копію, вносить у неї необхідні зміни та пов'язує дані з оновленою структурою лише після її успішного запису до сховища.
Відновлення: Завдяки методу Copy-on-Write попередня версія метаданих все ще залишається в сховищі, що дозволяє відновити до 100% видалених файлів, доки вони не були перезаписані новими даними.
Файлові системи macOS
Сьогодні Дискова утиліта (Disk Utility) від Apple дозволяє обирати серед кількох типів ФС. Спочатку файловою системою за замовчуванням для macOS була HFS+ (також відома як Mac OS Extended). Однак, починаючи з macOS High Sierra, компанія Apple перевела свої продукти на сучасну файлову систему APFS, розроблену та оптимізовану для сховищ на базі флеш-пам'яті. Вищеописаний формат exFAT, створений Microsoft, також може бути застосований на зовнішніх пристроях, які спільно використовуються різними платформами.
HFS+
Заголовок тому (Volume Header) розташовується на початку розділу HFS+. Він містить загальну інформацію про розділ, а також про розташування основних структур файлової системи. Ідентична копія Заголовка тому розміщується в кінці розділу.
Решта метаданих ФС представлені набором спеціальних файлів, які можуть зберігатися будь-де в межах розділу. Більшість із них організовані як B-дерева. Одне B-дерево складається з кількох вузлів, кожен з яких містить записи, що містять ключ і певні дані.
HFS+ розділяє весь простір для зберігання на одиниці однакового розміру, які називаються блоками розподілу. Щоб зменшити фрагментацію, ці блоки зазвичай виділяються безперервними групами (так звані clumps). У Файлі розподілу (Allocation File) фіксується, чи зайнятий кожен окремий блок розподілу в даний момент.
Для керування інформацією про вміст кожного файлу використовуються спеціальні структури: одна – для фактичних даних (потік даних або data fork), а інша – для додаткової інформації (потік ресурсу або resource fork). Безперервна послідовність блоків розподілу, виділена для потоку, називається екстентом. Один екстент представлений номером його початкового блоку та довжиною в блоках.
Файл каталогу (Catalog File) описує ієрархію всіх файлів і папок, а також їхні важливі властивості, як-то імена. У ньому також зберігаються перші вісім екстентів кожного потоку. Додаткові екстенти можна знайти у Файлі переповнення екстентів (Extents Overflow File). Інші властивості файлу містяться у Файлі атрибутів (Attributes File).
Крім того, HFS+ підтримує жорсткі посилання – численні посилання на один примірник вмісту файлу. Таке посилання є нічим іншим, як окремим файлом жорсткого посилання, створеним у Файлі каталогу для кожного запису каталогу. Тим часом оригінальний вміст переміщується до прихованого кореневого каталогу.
Усі зміни до ФС фіксуються в Журналі (Journal). Розмір Журналу в HFS+ обмежений: нова інформація додається та записується щоразу поверх старих записів журналу. Таким чином, HFS+ перезаписує старішу інформацію, щоб Журнал містив записи про нові зміни.
На малюнку нижче ви можете побачити, як пов'язані між собою ключові елементи структури HFS+ – Заголовок тому, Журнал і Файл каталогу:

Видалення
Процедура: HFS+ оновлює Файл каталогу шляхом реорганізації B-дерева, що може призвести до перезапису записів у вузлі, який відповідає видаленому файлові. Відповідні блоки у Файлі розміщення позначаються як вільні. Жорстке посилання видаляється із запису каталогу. Однак екстенти потоку даних залишаються у томі. Крім того, протягом певного часу ця інформація ще зберігається в Журналі.
Відновлення: Звернувшись до Журналу, можна знайти записи, що описують попередній стан оновлених блоків, та ідентифікувати метадані нещодавно видалених елементів. Шанси на успішне відновлення даних значною мірою залежатимуть від того, як довго система була у активному використанні після видалення. Навіть якщо ці записи Журналу були стерті, метод RAW-відновлення може забезпечити чудові результати у випадку нефрагментованих файлів. При цьому фрагментовані файли, що залишилися, створюватимуть проблему та призведуть до неповних результатів відновлення.
Форматування
Процедура: Файл каталогу скидається до ієрархії за замовчуванням, а отже, втрачає всі записи про попередні файли. З іншого боку, Журнал і сам вміст файлів залишаються недоторканими.
Відновлення: Програма для відновлення даних може звернутись до Журналу, щоб витягнути все, що можна відновити з його записів, а потім застосувати метод так званого RAW-відновлення, щоб відновити відсутні файли за допомогою попередньо визначених шаблонів. Аналогічним чином, шанси на успішне відновлення файлів будуть низькими, якщо вони дуже фрагментовані.
APFS
APFS використовує зовсім іншу стратегію організації даних. Том APFS завжди знаходиться в спеціальному Контейнері (Container). Один Контейнер може включати кілька томів (файлових систем), які спільно використовують доступний простір для зберігання даних. Усі зайняті та вільні блоки в Контейнері записуються за допомогою структур загальної Бітової мапи (Bitmap). У той же час кожен том має власний Суперблок (Superblock) і керує власними елементами, у яких зберігається інформація, як-от ієрархією каталогів, вмістом файлів і метаданими.
Розподіл файлів і папок представлений у вигляді B-дерева. Воно має ті самі функції, що й Файл каталогу в HFS+. Кожен елемент у дереві складається з кількох записів, а кожен запис зберігається як ключ і значення.
Вміст файлу складається принаймні з одного екстенту. Екстент містить інформацію про те, де починається вміст, і його довжину в блоках. Для всіх екстентів тому існує окреме B-дерево.
На відміну від HFS+, APFS ніколи не змінює жодних об'єктів прямо на місці. Замість цього вона створює їх копії та вносить необхідні зміни у нове місце на сховищі – принцип, відомий як Копіювання при записуванні (Copy-on-Write (CoW)).
Видалення
Процедура: APFS очищує відповідні вузли B-дерева розподілу файлів і папок.
Відновлення: Можна спробувати знайти старіші версії відсутніх вузлів і проаналізувати їх, щоб відновити їх попередні стани. Однак на пристроях Apple зазвичай за замовчуванням увімкнене шифрування, глибоко інтегроване у саму структуру APFS. Тож коли шифрування активоване, воно захищає не лише дані користувача, але й важливі структури метаданих, що значно ускладнює процес відновлення.
Файлові системи Linux
Linux, на відміну від Windows і macOS, є проєктом з відкритим кодом, розробленим спільнотою ентузіастів. Ось чому ця ОС пропонує так багато файлових систем на вибір: Ext2, Ext3, Ext4, ReiserFS, XFS, JFS, Btrfs і F2FS.
Ext2
Всі параметри цієї ФС можна знайти в Суперблоці (Superblock).
Ext2 ділить простір для зберігання даних на невеликі частини, які називаються блоками. Потім блоки впорядковуються у більші одиниці, які називаються Групами блоків (Block Groups). Інформація про всі Групи блоків доступна в Таблиці дескрипторів (Descriptor Table), яка зберігається одразу після Суперблоку. Кожна Група блоків також містить Бітові мапи блоків та індексних дескрипторів (Block Bitmap та Inode Bitmap) для відстеження стану власних блоків та індексних дескрипторів (inode) відповідно.
Індексний дескриптор є основним елементом у Ext2. У таких дескрипторах містяться описи кожного файлу та папки у ФС, включно з їх розмірами і розташування блоків, у яких зберігаються їхні фактичні дані. Індексні дескриптори для кожної Групи блоків зберігаються в її Таблиці індексних дескрипторів (Inode Table).
Однак у цій ФС ім'я файлу не вважається метаданими. Імена зберігаються окремо в спеціальних файлах-каталогах разом із номерами відповідних індексних дескрипторів.
На малюнку нижче ви можете побачити взаємозв'язок між ключовими елементами структури Ext2 – Суперблоком, Групами блоків, Таблицями індексних дескрипторів та індексними дескрипторами:

Видалення
Процедура: Ext2 позначає індексний дескриптор, що описує файл, як вільний, і оновлює Бітові мапи блоків та індексних дескрипторів. Запис, який пов'язує ім'я файлу з певним номером індексного дескриптора, видаляється з файлу-каталогу.
Відновлення: Із інформацією, яка залишається в індексному дескрипторі, шанси відновити файл досить високі. Однак, оскільки ім'я файлу не зберігається в індексному дескрипторі і посилання на нього більше не існує, воно, ймовірно, буде остаточно втрачене.
Форматування
Процедура: Ext2 стирає існуючі Групи блоків і видаляє індексні дескриптори.
Відновлення: Метод RAW-відновлення можна застосувати для відновлення файлів за їх відомим вмістом. Шанси на відновлення значною мірою залежать від ступеня фрагментації: фрагментовані файли можуть бути пошкоджені.
Ext3/Ext4
Основна перевага файлової системи Ext3 над Ext2 полягає в тому, що вона застосовує журналювання. Журнал реалізований як спеціальний файл, який відстежує всі зміни у файловій системі.
Ext4 народилась в результаті розширення Ext3 за допомогою нових структур файлової системи. Найвиразніша з цих структур називається екстентом. Замість того, щоб розподіляти вміст по окремих блоках, Ext4 намагається розмістити якомога більше даних у безперервній області. Ця область описується адресою її початкового блоку та її загальною довжиною в блоках. Такі екстенти можуть зберігатись безпосередньо в індексному дескрипторі. Проте, якщо файл має більше чотирьох екстентів, решта з них групуються у B+-дерево.
Ext4 також використовує відкладений розподіл: вона збирає дані, які потрібно записати до сховища перед тим, як фактично виділити для них простір, і у такий спосіб зводить фрагментацію до мінімуму.
На малюнку нижче проілюстрований взаємозв'язок між ключовими елементами структури Ext3/Ext4 – Суперблоком, Журналом, Групами блоків, Таблицями індексних дескрипторів, індексними дескрипторами:

Видалення
Процедура: ФС створює запис у Журналі, а потім стирає пов'язаний з файлом індексний дескриптор. Запис каталогу не видаляється повністю, скоріше змінюється порядок читання каталогу.
Відновлення: Відновлення видалених файлів навіть із початковими назвами цілком можливе за допомогою записів Журналу. Менше з тим, якість результату відновлення залежить від часу, протягом якого файлова система залишалась у роботі після видалення даних.
Форматування
Процедура: Очищуються всі Групи блоків, а також індексні дескриптори файлів і навіть Журнал. Незважаючи на це, Журнал все ще може містити інформацію про деякі нещодавно створені файли.
Відновлення: Відновлення втрачених файлів можливе лише за допомогою методу RAW-відновлення. При цьому шанси дуже низькі у разі, якщо вони фрагментовані.
ReiserFS
Том ReiserFS розділений на блоки фіксованого розміру. Найважливіша інформація про нього доступна в Суперблоці (Superblock). Безпосередньо після Суперблоку йде бітова карта використаних і вільних блоків.
Ця ФС повністю покладається на структуру під назвою S+-дерево, що складається з внутрішніх і листових вузлів. Таке дерево використовується для організації всіх файлів, папок і метаданих. У дереві є чотири основні типи елементів: непрямі та прямі, елементи каталогу та елементи статистики. Прямі елементи містять фактичні дані, тоді як непрямі просто вказують на певні блоки даних. Елементи каталогу представляють записи в каталозі, а елементи статистики містять відомості про файли та папки. Кожному елементу присвоюється унікальний ключ, за яким його можна знайти у дереві. Ключ містить ідентифікатор, адресу та тип елемента.
ReiserFS застосовує спеціальний механізм, який називається tail-packing ("пакування хвостів"). Вона об'єднує файли та фрагменти файлів, менші за повний блок, і зберігає їх безпосередньо в листових вузлах S+-дерева. Такий підхід зменшує кількість марно витраченого простору та знижує ступінь фрагментації.
У Журналі фіксуються всі зміни, внесені у файлову систему. Замість того, щоб вносити зміни безпосередньо в S+-дерево, ReiserFS спочатку записує їх у Журнал. Пізніше вони копіюються з Журналу до фактичного місця розташування на сховищі. Таким чином, ReiserFS може зберігати багато копій метаданих.
На малюнку нижче ви можете побачити взаємозв'язки між ключовими елементами структури ReiserFS – Суперблоком, S+-деревом і елементами дерева:

Видалення
Процедура: ReiserFS оновлює S+-дерево, щоб виключити файл, і змінює статус відповідних блоків у бітовій мапі.
Відновлення: Оскільки копія S+дерева зберігається, можна відновити всі файли разом з їхніми іменами. Крім того, зі старішої копії S+-дерева можна навіть отримати попередню версію файлу.
Форматування
Процедура: ReiserFS створює нове S+-дерево поверх існуючого.
Відновлення: Попереднє S+-дерево можна відновити з копії, що гарантує повне відновлення даних. Однак шанси зменшуються, якщо розділ був заповнений. У такій ситуації файлова система може записати нову інформацію поверх старих даних.
XFS
XFS складається з областей однакового розміру, які називаються Групами розподілу (Allocation Groups). Кожна Група розподілу поводиться як окрема файлова система, яка має власний Суперблок, керує власними структурами та контролює використання простору для зберігання даних.
Вільний простір відстежується за допомогою пари B+-дерев: перше вказує на початковий блок безперервної області вільного простору, а друге – на кількість блоків у ній. Подібний підхід на основі екстентів використовується для відстеження блоків, призначених кожному файлу.
Усі файли та папки в XFS представлені спеціальними індексними дескрипторами, які містять їхні метадані. Якщо можливо, розподіл екстентів зберігається безпосередньо в індексному дескрипторі. Екстенти дуже великих або фрагментованих файлів відстежуються іншим B+-деревом, пов'язаним з індексним дескриптором. Окреме B+-дерево використовується в кожній Групі розподілу для ведення обліку цих індексних дескрипторів під час їх виділення та звільнення.
Як і багато подібних файлових систем, XFS не зберігає ім'я файлу в індексному дескрипторі. Воно присутнє лише в записі каталогу.
XFS застосовує журналювання до операцій з метаданими. Зміни до ФС зберігаються у Журналі, доки фактичні оновлення не будуть застосовані.
На малюнку нижче показаний взаємозв'язок між ключовими елементами структури XFS – Групами розподілу, Суперблоками, структурами B+-дерев, індексними дескрипторами:

Видалення
Процедура: Відповідальний за файл індексний дескриптор виключається з B+-дерева; більшість інформації в ньому перезаписується, але дані у екстенті залишаються незмінними. Посилання від запису каталогу на ім'я файлу втрачається.
Відновлення: XFS зберігає копії метаданих у Журналі, сприяючи успішному відновленню втрачених файлів. Шанси повернути їх, навіть із правильними іменами, досить високі.
Форматування
Процедура: B+-дерева, які керують розподілом простору, очищаються, а новий кореневий каталог перезаписує наявний.
Відновлення: Шанси відновити файли, які були розташовані далеко від початку сховища, високі, на відміну від тих, що зберігалися близько до нього.
JFS
Основна інформація про JFS міститься у Суперблоці (Superblock).
Том JFS може складатися з кількох областей, які називаються Групами розподілу (Allocation Groups). Кожна Група розподілу має один або кілька Наборів файлів (FileSets).
Кожен файл і папка у цій файловій системі описується відповідним індексним дескриптором. Окрім ідентифікаційної інформації, індексний дескриптор також містить вказівку на місце, де зберігається вміст файлу. Сам вміст представлено одним або кількома екстентами. Екстент складається з одного або кількох суміжних блоків. Усі екстенти індексуються за допомогою спеціального B+-дерева.
Вміст невеликих каталогів зберігається в їх індексних дескрипторах, тоді як більші каталоги організовані як B+-дерева.
Вільний простір у JFS також відстежується за допомогою B+-дерев: одне дерево зберігає початкові блоки вільних екстентів, а друге записує кількість вільних екстентів.
JFS має спеціальну область журналу (log area) та робить записи до Журналу щоразу, коли відбувається зміна метаданих.
На малюнку нижче можна побачити співвідношення між ключовими елементами структури JFS – Суперблоком, Групою розподілу, Набором файлів, B+-деревами, Журналом, індексними дескрипторами:

Видалення
Процедура: JFS оновлює B+-дерево вільного простору та звільняє пов'язаний із файлом індексний дескриптор. Каталог перебудовується, щоб відобразити зміни.
Відновлення: Індексний дескриптор залишається на сховищі, збільшуючи шанси на відновлення файлів майже до 100%. Шанси на відновлення низькі лише для імен файлів.
Форматування
Процедура: JFS створює нове B+-дерево. Воно невелике спочатку і розширюється з подальшим використанням файлової системи.
Відновлення: Шанси відновити втрачені файли після форматування досить високі з огляду на малий розмір нового B+-дерева.
Btrfs
Як і багато інших файлових систем, Btrfs починається з Суперблоку (Superblock), який надає важливу інформацію про її організацію.
Інші елементи представлені як B-дерева, кожне з яких має своє призначення. Розташування кореневого B-дерева (Root B-tree) можна знайти у Суперблоці, а це дерево, у свою чергу, містить посилання на решту B-дерев. Будь-яке B-дерево складається з внутрішніх вузлів і листів: внутрішній вузол зв'язаний з дочірнім вузлом або листом, тоді як лист містить певний елемент із фактичною інформацією. Точна структура та вміст елемента залежить від типу даного B-дерева.
Однією із визначних особливостей Btrfs є те, що вона може поширюватися на кілька пристроїв, простір яких об'єднується в єдиний спільний пул. Після цього кожному блоку фізичного сховища присвоюється віртуальна адреса. Саме ці адреси, а не справжні, потім використовуються іншими структурами ФС. Інформація про відповідність між віртуальною та фізичною адресами доступна в B-дереві фрагментів (Chunk B-tree). Воно також "знає", які пристрої утворюють пул. B-дерево пристроїв (Device B-tree), навпаки, пов'язує фізичні блоки пристроїв з їхніми віртуальними адресами.
B-дерево файлової системи (File System B-tree) організовує всю інформацію про файли та папки. Дуже маленькі файли можуть зберігатися безпосередньо в дереві всередині екстентів. Файли більшого розміру зберігаються назовні в суміжних областях, які називаються екстентами. У цьому випадку елемент екстенту посилається на всі екстенти, у яких знаходяться фактичні дані файлу. Елементи каталогу складають вміст папок, а також включають імена файлів і вказують на їхні індексні дескриптори. Останні використовуються для зберігання інших властивостей, таких як розмір, дозволи тощо.
B-дерево екстентів відстежує виділені екстенти в елементах екстентах. Тобто воно слугує картою вільного простору.
В описаних B-деревах зміни ніколи не застосовуються прямо на місці. Натомість змінена інформація записується до іншого місця. Ця техніка відома як Копіювання при записуванні (Copy-on-Write).
Тим не менш, на твердотільних накопичувачах Btrfs може виявляти екстенти, позначені як невикористані, і автоматично стирати їх, запускаючи команду TRIM.
Видалення
Процедура: Brtfs перебудовує B-дерево файлової системи, щоб виключити з нього індексні дескриптори, пов'язані з видаленим файлом, і звільняє екстенти, виділені йому в B-дереві екстентів. Усі пов'язані структури оновлюються.
Відновлення: Потрібні елементи більше не є частиною структури ФС. Проте, оскільки Brtfs покладається на принцип Copy-on-Write, можна отримати доступ до старих копій, включно з попередньою версію B-дерева файлової системи, проаналізувати їх і успішно відновити видалений файл за умови, що його вміст і метадані ще не були перезаписані.
F2FS
F2FS розроблено з урахуванням особливостей флеш-пам'яті. Вона розбиває весь простір для зберігання даних на сегменти фіксованого розміру. Секція складається з послідовних сегментів, а набір секцій утворює зону.
Суперблок (Superblock) знаходиться на початку розділу F2FS. Він містить основну інформацію про розділ та про розташування важливих областей у ньому. У цій системі створюється ще одна копія Суперблоку для резервного копіювання. Блоки контрольних точок (Checkpoint blocks) зберігають точки відновлення попереднього та поточного стану важливих елементів файлової системи.
Розміщення даних здійснюється за допомогою спеціальних структур-вузлів. Ці вузли можуть бути трьох типів: прямі та непрямі вузли, та індексні дескриптори. Прямий вузол зберігає адреси блоків з фактичними даними, непрямий посилається на блоки в інших вузлах, а індексний дескриптор містить метадані, включно з іменем файлу, розміром та іншими властивостями. Зіставлення вузлів та їх фізичних місць розташування у файловій системі зберігається в Таблиці адрес вузлів (Node Address Table чи NIT).
Вміст файлів і папок зберігається в Основній області (Main Area). Секції у ній відокремлюють блоки, які містять дані, від блоків вузлів з інформацією про індексування. Статуси використання всіх типів блоків відображаються в Таблиці інформації про сегмент (Segment Information Table або SIT): ті, що використовуються, позначаються як дійсні, а ті, що містять видалені дані, вважаються недійсними. Область зведення сегментів (Segment Summary Area чи SSA) фіксує, які блоки належать до якого вузла.
Записи каталогу у F2FS називаються dentries. Dentry містить ім'я файлу та номер його індексного дескриптора.
F2FS запускає процес очищення, коли їй бракує вільних сегментів, а також у фоновому режимі, коли перебуває у неактивному стані. Сегменти-жертви в цьому випадку вибираються за кількістю використаних блоків відповідно до SIT або за їх "віком".
Видалення
Процедура: Зміни вносяться до Таблиці адрес вузлів і Таблиці інформації про сегмент. Ця інформація зберігається в пам'яті, поки нова контрольна точка створюється та записується в Блок контрольної точки. Вміст звільнених блоків зберігається на сховищі до стирання в процесі очищення.
Відновлення: За допомогою останньої контрольної точки можна отримати доступ до попереднього стану метаданих файлової системи та знайти вузол і блоки даних, пов'язані з файлом, якщо вони не були перезаписані.
Файлові системи BSD, Solaris, Unix
Ці Unix-подібні операційні системи пропонують два власні формати – UFS, що існує з перших днів, і сучасну файлову систему ZFS.
UFS
Том UFS складається з однієї або кількох Груп циліндрів (Cylinder Groups). Їх розташування та інші важливі деталі, пов'язані з файловою системою, доступні у Суперблоці (Superblock). Резервна копія Суперблоку зберігається в кожній Групі циліндрів.
Будь-який файл в UFS складається з індексного дескриптора та блоків даних із його фактичним вмістом. Індексний дескриптор містить усі властивості файлу, окрім його імені, яке зберігається в каталозі. Він також вказує безпосередньо на перші 12 блоків даних файлу. Якщо файл більший, наступна адреса натомість вказує на непрямі блоки, які містять адреси прямих блоків.
В UFS каталоги представлені групами записів, у яких зберігається список імен файлів із номерами індексних дескрипторів для кожного з них. Хоча файл завжди пов'язаний з одним індексним дескриптором, у випадку жорстких посилань той самий файл може мати кілька імен. Якщо імена файлів у різних каталогах вказують на той самий індексний дескриптор, кількість посилань відображається в індексному дескрипторі.
Кожна Група циліндрів зберігає власні бітові мапи вільних блоків і вільних індексних дескрипторів. Крім того, існує певна кількість індексних дескрипторів, які містять файлові атрибути. Решту місця у групі циліндрів займають блоки даних.
Видалення
Процедура: UFS стирає індексний дескриптор видаленого файлу і оновлює бітові мапи вільних блоків і вільних індексних дескрипторів. Потім відповідний запис видаляється з каталогу.
Відновлення: Без індексного дескриптора не залишається інформації про розмір файлу та перші 12 блоків даних. Посилання на його ім'я також остаточно втрачається. Дані все ще можна відновити за допомогою методу RAW-відновлення. Однак у випадку фрагментованих файлів шанси досить низькі.
ZFS
На відміну від більшості файлових систем, ZFS може охоплювати низку фізичних дисків, об'єднаних у пул зберігання. Пул можуть складати один або кілька віртуальних пристроїв, які називаються vdev. Vdev має мітку, що його описує, із чотирма копіями, які зберігаються задля безпеки. Усередині кожної мітки vdev є Уберблок (Uberblock). Подібно до Суперблоку, який використовується іншими типами файлових систем, він містить важливу інформацію, необхідну для доступу до всього вмісту.
Простір для зберігання даних розподіляється у одиницях змінного розміру, які називаються блоками. Усі блоки в ZFS організовані як об'єкти різних типів. Об’єкти характеризуються особливими структурами, які називаються dnode. Dnode описує тип об'єкта, його розмір, а також набір блоків, у яких містяться його фактичні дані. Він може містити до трьох вказівників (або покажчиків) на блоки. Вказівник — це базова структура, яка використовується ZFS для адресації блоку, він може вказувати або на кінцевий листовий блок, який містить фактичну інформацію, або на непрямий блок, який вказує на інший блок.
Пов'язані об'єкти надалі групуються в набори об'єктів. Кожен об'єкт у наборі однозначно ідентифікується за номером об'єкта. Прикладом набору об'єктів є файлова система, яка містить об'єкти-файли та об'єкти-каталоги. Набір dnode, які описують об'єкти в даному наборі об'єктів, також зберігається як об'єкт, на який вказує metadnode. Метадані, які стосуються всього пулу, містяться в наборі об'єктів під назвою Мета набір об'єктів (Meta Object Set чи MOS).
Коли ZFS записує будь-які дані до сховища, блоки ніколи не перезаписуються на місці. Спочатку вона виділяє новий блок у іншому місці. Після завершення операції метадані ФС оновлюються, щоб вказувати на щойно записаний блок, у той час як його стара версія також зберігається.
Видалення
Процедура: ZFS від'єднує блоки даних від об'єкта-файлу та відповідного dnode. Номер об'єкта стає доступним для повторного використання. Файл видаляється зі списку в об'єкті-каталозі. Уберблок замінюється на новий.
Відновлення: Оскільки ZFS використовує техніку Копіювання при записуванні (Copy-on-Write (CoW)), старі копії можуть залишатися в пулі, що дозволяє провести успішне відновлення видалених файлів. Однак дані розкидані по дисках у вигляді блоків різного розміру, тому процедуру неможливо виконати без неушкоджених метаданих пулу, що є важливим для правильного повторного складання останнього.
Як TRIM впливає на шанси відновити дані?
Більшість сучасних SSD-накопичувачів і велика кількість нових жорстких дисків SMR у своїй роботі покладаються на внутрішній рівень трансляції, який підтримує команду TRIM. Якщо увімкнути TRIM, файлова система почне інформувати диск про те, що певні блоки більше не використовуються. Ці блоки потім позначаються як вільні та такі, що мають бути очищені під час так званого збирання сміття, процесу, під час якого дані стираються фізично. Такий підхід допомагає покращити продуктивність і продовжити строк служби накопичувача, але також робить відновлення видалених або відформатованих даних надзвичайно складним, а у більшості випадків навіть практично неможливим.
Щойно TRIM надсилається, диск починає розглядати вищезгадані блоки як порожні. Навіть якщо дані ще не були фізично стерті, всі посилання на них видаляються на внутрішньому рівні відображення даних диска. В результаті файли стають невидимими як для операційної системи, так і для програмного забезпечення для відновлення даних. Коли збирання сміття врешті-решт запускається, дані безповоротно знищуються і більше не можуть бути відновлені.
Збирання сміття не завжди відбувається миттєво. Строки його виконання залежать від моделі диска, типу пам'яті та робочого навантаження. Це може відбутися протягом секунд, годин або навіть днів. Однак внутрішнє відображення даних оновлюється майже миттєво, і диск зазвичай повертає нулі під час зчитування зачеплених цією командою областей ще до того, як дані фізично зітруться.
Видалення
Процедура: Файлова система позначає зайнятий простір як доступний для повторного використання та невдовзі після цього надсилає команду TRIM. Диск оновлює своє внутрішнє відображення даних, щоб позначити, що відповідні блоки більше не використовуються і їх можна прибрати під час збору сміття. Фактичне стирання інформації може відбутися як негайно, так і з затримкою від кількох секунд до кількох днів.
Відновлення: Зазвичай є лише дуже короткий проміжок часу (часто лише кілька секунд), протягом якого відключення диска може завадити оновленню транслятора. Після виконання TRIM програмне забезпечення для відновлення файлів більше не матиме змоги отримати доступ до даних. У рідкісних випадках фахівці з відновлення даних можуть використати спеціалізоване обладнання, яке обходить рівень трансляції диска та зчитує необроблену інформацію безпосередньо з мікросхем пам'яті. Однак успіх цих маніпуляцій не гарантований і залежить від багатьох технічних факторів. Якщо ж диск залишиться ввімкненим, операція збору сміття зрештою повністю видалить дані.
Форматування
Процедура: Структури файлової системи скидаються і TRIM зазвичай виконується для всіх раніше використовуваних блоків. Диск відповідно оновлює своє внутрішнє відображення даних, позначаючи ці блоки як вільні. Збір сміття може розпочатися негайно або через певний час, залежно від внутрішнього стану диска та його робочого навантаження.
Відновлення: Як і у випадку з видаленням файлів, вимкнення диска до того, як розпочнеться збір сміття, може залишити крихітний шанс на відновлення необроблених даних кваліфікованими спеціалістами. Після того, як збір сміття був проведений, дані втрачаються назавжди.
Пошкодження метаданих
Процедура: Коли метадані файлової системи пошкоджуються, ОС буває втрачає змогу відстежувати певні блоки, тож і не виконує для них команду TRIM. Без цієї команди диск не оновлює стан цих блоків і їх не зачіпає операція зі збору сміття.
Відновлення: Оскільки TRIM не виконується, дані в цих блоках часто залишаються недоторканими, навіть якщо до них більше не можна отримати доступ через операційну систему. У таких випадках програмне забезпечення для відновлення даних може знайти та відновити втрачені файли, хоча шанси на це залежать від ступеня пошкодження та типу застосованої файлової системи.
Насамкінець варто зазначити, що розуміння того, як саме файлові системи впливають на відновлення даних, є безперечно важливим, але в багатьох випадках наявність правильних інструментів під рукою також може суттєво вплинути на ситуацію. Щоб максимізувати шанси на успіх, особливо під час роботи зі складними або малопоширеними файловими системами, варто використати професійне програмне забезпечення для відновлення даних від SysDev Laboratories. Ці рішення розроблені для роботи з різноманітними файловими системами та конфігураціями сховищ, пропонуючи можливості, що помітно перевищують ті, що їх можуть надати більшість базових утиліт для відновлення.