In welcher Beziehung steht ein Dateisystem zum Datenrettungspotenzial?
Zunächst einmal enthält jedes nutzbare Speichergerät, von einer winzigen Speicherkarte bis hin zu einer sperrigen internen Festplatte, eine oder mehrere Partitionen. Hierbei handelt es sich um Regionen auf demselben physischen Medium, die vom Betriebssystem erstellt und als separate logische Datenträger behandelt werden. Die Informationen darüber werden normalerweise am Anfang des Laufwerks in einem speziellen Element namens Partitionstabelle gespeichert.
Jede Partition ist unabhängig von den anderen und verfügt über ein eigenes Dateisystem. Dies ist der Hauptmechanismus, der für die Datenplatzierung innerhalb der Grenzen einer Partition verantwortlich ist. Dadurch bleiben die Daten geordnet und können jederzeit leicht abgerufen werden.
Allerdings sind die Dateisysteme nicht alle gleich, sie können unterschiedliche Prinzipien für die Organisation des Speicherplatzes haben. Eindeutige Instanzen werden meist als Typen oder seltener als Formate bezeichnet. Der Typ kann automatisch vom Betriebssystem oder vom Benutzer aus den vorgeschlagenen Optionen ausgewählt werden.
Jeder Dateisystemtyp trennt die Daten, aus denen Dateien bestehen, von den diesen Inhalt beschreibenden Informationen, den sogenannten Metadaten. Diese umfassen den Namen, die Größe, den Speicherort, die Position der Datei in der Verzeichnisstruktur und andere Eigenschaften, die zur Identifizierung der Datei beitragen. Gleichzeitig können die Regeln, nach denen sie diese technischen Daten speichern, erheblich variieren.
Das Dateisystem regelt nicht nur die Art und Weise, wie Informationen zugewiesen werden, sondern definiert auch die Methode, wie diese beim Löschen oder bei der Formatierung des Speichers verarbeitet werden. In der Regel wird der Inhalt von Dateien nicht sofort zerstört, sondern die Metadaten werden gelöscht oder geändert, um zu verdeutlichen, dass es jetzt an der Zeit ist, sie zu entfernen. Daher hängen die Erfolgsaussichten im Falle von Pannen und Wiederherstellungsbedarf drastisch vom Verhalten des eingesetzten Dateisystems ab.
Wenn Sie aufgrund eines unglücklichen Fehlers einige Daten gelöscht haben oder das gesamte Volumen formatiert wurde, können Sie die Möglichkeit, die Dinge in Ordnung zu bringen, abschätzen, wenn Sie wissen, welcher Dateisystemtyp diesen Vorgang tatsächlich durchgeführt hat. Schauen wir uns daher die verschiedenen Formate von Windows (NTFS, FAT/FAT32, exFAT, ReFS), macOS (HFS+, APFS), Linux (Ext2, Ext3, Ext4, ReiserFS, XFS, JFS) und BSD/Solaris/ Unix (UFS, ZFS) genauer an, ihre allgemeine Struktur sowie Lösch- und Formatierungspraktiken.
Die Dateisysteme von Windows
Microsoft Windows bietet derzeit zwei Formate für seine internen Laufwerke an: NTFS und Server-Grade ReFS. Externe Speichergeräte wie USB-Sticks und Speicherkarten verwenden normalerweise FAT/FAT32 oder exFAT.
NTFS
Der Anfang einer NTFS-Partition wird vom Volume Boot Record (VBR) belegt. Diese Datei enthält Informationen zur Größe und Struktur des Dateisystems sowie den Bootcode.
NTFS manipuliert Daten mithilfe der Meisterdateitabelle (Master File Table oder MFT). Im Grunde handelt es sich um eine Datenbank, die Datensätze für alle im Dateisystem vorhandenen Dateien und Ordner enthält. Jeder MFT-Datensatz umfasst eine Vielzahl von Attributen wie Standort, Name, Größe, Datum/Uhrzeit der Erstellung und letzte Änderung. Die Meisterdateitabelle selbst verfügt über das Bitmap-Attribut, das angibt, welche Datensätze derzeit benutzt werden.
Sehr kleine Dateien werden als Attribute sofort in der MFT-Zelle gespeichert. Wenn der Inhalt groß ist, wird er außerhalb des MFT gespeichert, während der Datensatz auf seinen Speicherort verweist. Wenn die Attribute nicht in einen einzelnen MFT-Datensatz passen, werden sie ebenfalls aus der Tabelle verschoben und nur ihre Adressen bleiben dort erhalten.
Ordner in NTFS werden durch Verzeichniseinträge dargestellt. Dabei handelt es sich tatsächlich um Dateien, die eine Liste anderer Dateien mit Verweisen darauf enthalten.
Eine weitere wichtige Datei für NTFS ist die Bitmap. Sie verfolgt alle belegten und freien Speicherorte im Dateisystem.
Auf dem Bild unten sehen Sie die Beziehung zwischen den Schlüsselelementen der NTFS-Struktur – dem Volume Boot Record ($Boot), der Meisterdateitabelle ($MFT) und dem Dateninhaltsbereich:

Löschung
Prozedur: NTFS behält den MFT-Datensatz für die Datei bei, kennzeichnet es ihn jedoch als nicht verwendet und markiert den Speicherort, an dem sich ihr Inhalt befindet, als freigegeben in der Bitmap. Die Datei wird auch aus dem Verzeichniseintrag entfernt.
Wiederherstellung: Der Name, die Größe und der Speicherort der Datei sollten im MFT-Datensatz belassen werden. Bleibt dieser unverändert und wurde der Dateninhalt nicht überschrieben, liegen die Wiederherstellungschancen bei 100 %. Fehlt dieser Eintrag, ist es unter Umständen trotzdem möglich, die Datei unter Umgehung der Dateisystemstruktur mithilfe der RAW-Wiederherstellungsmethode zu finden. In diesem Fall werden die Rohdaten auf dem Laufwerk auf das Vorhandensein vordefinierter Muster analysiert, die Dateien des angegebenen Typs charakterisieren. Der größte Nachteil dieses Ansatzes ist jedoch das Fehlen der ursprünglichen Namen und Ordnerstruktur in den Ergebnissen.
Formatierung
Prozedur: Es wird eine neue Meisterdateitabelle erstellt, die den Anfang der vorhandenen MFT-Tabelle löscht. Der Rest bleibt jedoch unberührt.
Wiederherstellung: Die ersten 256 Dateien sind in der Meisterdateitabelle nicht mehr vertreten, daher ist deren Rettung nur noch mit der RAW-Wiederherstellungsmethode möglich. Die Wiederherstellbarkeit von Dateien, die diesen 256 folgen, beträgt bis zu 100 %.
FAT/FAT32
Die grundlegenden Informationen über die Dateisystemorganisation sind im Bootsektor ganz am Anfang der Partition verfügbar.
FAT/FAT32 unterteilt den Speicherplatz in gleich große Teile, sogenannte Cluster. Der Inhalt einer Datei kann einen oder mehrere Cluster annehmen, die nicht unbedingt nahe beieinander liegen. Die Dateien, deren Inhalt nicht sequentiell gespeichert ist, werden als fragmentiert bezeichnet.
Die Dateizuordnungstabelle (File Allocation Table oder FAT) verfolgt, welche Cluster von welchen Dateien gebraucht werden. Normalerweise werden zwei Kopien der Tabelle zu Sicherungszwecken gespeichert. Jeder Cluster verfügt über einen eigenen Eintrag in der Dateizuordnungstabelle, der angibt, ob er belegt ist. Wenn ja, gibt es auch einen Link zum nächsten Cluster, der zur selben Datei gehört, oder eine Markierung, dass es sich um den letzten Cluster in der Kette handelt.
Das Stammverzeichnis besteht aus einer Reihe von Einträgen, die alle Dateien und Ordner beschreiben. Jeder Verzeichniseintrag umfasst den Startcluster, den Namen, die Größe und andere Attribute der Datei. Die Nummer dieses Clusters weist auch auf einen Eintrag in der FAT-Tabelle hin.
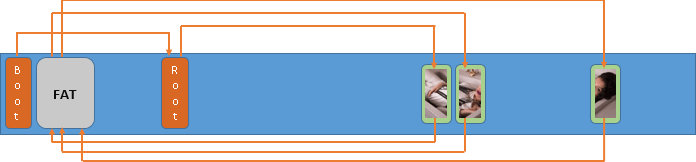
Auf dem Bild unten sehen Sie die Beziehung zwischen den Schlüsselelementen der FAT/FAT32-Struktur – dem Bootsektor, zwei Dateizuordnungstabellen, dem Root-Verzeichnis und dem Datenbereich:

Löschung
Prozedur: FAT/FAT32 markiert den Verzeichniseintrag der Datei als gelöscht und wischt alle in den entsprechenden FAT-Tabelleneinträgen enthaltenen Informationen ab, wodurch die Verknüpfungen zu den Zwischen- und Endclustern zerstört werden. Das erste Zeichen des Dateinamens wird durch einen Wert ersetzt, der den Löschstatus angibt. FAT32 löscht auch teilweise die Informationen zum Startcluster.
Wiederherstellung: Der erste Cluster und die Größe sind im Verzeichniseintrag zu finden, der Standort des Zwischen- und Endclusters muss jedoch angenommen werden. Aus diesem Grund ist die Datenwiederherstellung möglicherweise unvollständig. Außerdem führt FAT/FAT32 keine Defragmentierung durch, was die Rettung von Dateien mit der RAW-Wiederherstellungsmethode erschwert. Ein weiteres Problem besteht darin, dass Dateinamen in ihrer Länge begrenzt sind und sogar getrennt auf dem Speicher gespeichert werden können. Die Wiederherstellung langer Namen hat möglicherweise keine Wirkung.
Formatierung
Prozedur: Beide Kopien der FAT-Tabelle werden ausgeräumt und das Stammverzeichnis wird gelöscht. Der Dateninhalt ist jedoch immer noch vorhanden.
Wiederherstellung: Wie im vorherigen Szenario können aufeinanderfolgende Dateien mithilfe der RAW-Wiederherstellungsmethode wiedererlangen werden. Aufgrund des Fragmentierungsproblems kann sich jedoch herausstellen, dass ein großer Teil der Daten beschädigt ist.
exFAT
exFAT wurde als Nachfolger von FAT/FAT32 entwickelt und ähnelt daher stark den Dateisystemen dieser Familie. Der Aufbau eines exFAT-Volumens wird ebenfalls im Bootsektor beschrieben. Aus Sicherheitsgründen wird eine weitere Kopie des Bootsektors gespeichert.
exFAT wendet auch die Dateizuordnungstabelle an, es gibt jedoch nur eine Kopie davon und sie enthält nur Links für fragmentierte Dateien. Außerdem wird der Status von Clustern nicht direkt im Eintrag angezeigt, sondern mithilfe einer speziellen Zuordnungsbitmap (Allocation Bitmap) verwaltet. Diese Bitmap wird im Datenbereich gespeichert und zeigt an, ob der Cluster benutzt oder zum Schreiben bereit ist. Solcher Ansatz macht es für exFAT einfacher, zusammenhängende Cluster zu finden, um den Inhalt der Datei zu platzieren und so Fragmentierung zu verhindern.
Verzeichniseinträge werden auf die gleiche Weise wie in FAT/FAT32 behandelt, es gibt jedoch auch einen speziellen Eintrag im Stammverzeichnis, der die Informationen über die Zuordnungsbitmap speichert.
Auf dem Bild unten sehen Sie die Beziehung zwischen den Schlüsselelementen der exFAT-Struktur – dem Bootsektor, der Dateizuordnungstabelle, dem Stammverzeichnis und dem Datenbereich:
Löschung/Formatierung
Prozedur: exFAT ändert den Status der zugehörigen Cluster in der Zuordnungsbitmapdatei. Die FAT-Einträge werden nicht sofort aktualisiert, um unnötige Schreibvorgänge zu vermeiden. Der Datenbereich wird ebenfalls nicht ausgeräumt.
Wiederherstellung: Wenn die Datei fragmentiert war, kann die Kette ihrer Cluster mithilfe der verbleibenden FAT-Einträge rekonstruiert werden. Falls diese Links verloren gehen, ist die Datenrettung möglicherweise unvollständig. Dennoch kann die RAW-Wiederherstellungsmethode aufgrund der geringeren Fragmentierung für exFAT im Vergleich zu FAT/FAT32 positive Ergebnisse liefern.
ReFS
Das Layout von ReFS unterscheidet sich erheblich von den übrigen Formaten von Microsoft Windows. Die darin enthaltenen Informationen werden im Allgemeinen in Form von B+Bäumen organisiert, die ähnlich wie Datenbanken funktionieren. B+Bäume werden für fast alle Elemente im Dateisystem gebraucht, einschließlich des Inhalts von Dateien und Metadaten. Ein solcher Baum besteht aus der Wurzel, den inneren Knoten und den Blättern. Jeder Baumknoten verfügt über eine geordnete Liste von Schlüsseln und Zeigern auf die Knoten der unteren Ebene oder Blätter.
Das Verzeichnis ist die Hauptkomponente des Dateisystems. Es wird ebenfalls durch einen B+-Baum dargestellt. Der darin enthaltene Schlüssel entspricht der Nummer eines Ordnerobjekts. Eine Datei wird nicht als separates Element des Verzeichnisses behandelt und liegt in Form eines Datensatzes vor.
Ein weiteres bemerkenswertes Merkmal von ReFS ist die Verwendung von Copy-on-Write (CoW) – die ursprünglichen Einträge des Dateisystems werden nie sofort geändert, sondern lediglich kopiert und zusammen mit den erforderlichen Änderungen an einen neuen Speicherort geschrieben.
Löschung
Prozedur: Die Metadatenstruktur sollte als Reaktion auf das Löschen der Datei neu aufgebaut werden. ReFS bearbeitet sie jedoch nicht sofort. Stattdessen erstellt es ihre Kopie, nimmt die erforderlichen Änderungen vor und verknüpft die Daten erst dann mit der aktualisierten Struktur, wenn sie erfolgreich in den Speicher geschrieben wurden.
Wiederherstellung: Dank der Copy-on-Write-Methode verbleibt die vorherige Version der Metadaten weiterhin auf dem Speicher, sodass bis zu 100 % der gelöschten Dateien wiederhergestellt werden können, bis sie mit neuen Daten überschrieben werden.
Die Dateisysteme von macOS
Heutzutage ermöglicht das Festplattendienstprogramm von Apple die Auswahl aus mehreren Dateisystemtypen. HFS+ (auch bekannt als Mac OS Extended) war ursprünglich das Standarddateisystem für macOS. Mit macOS High Sierra stellte Apple jedoch auf das moderne APFS-Dateisystem um, das speziell für Flash-Speicher entwickelt und optimiert wurde. Das zuvor beschriebene exFAT-Format, obwohl von Microsoft entwickelt, kann auch auf externen Geräten angewendet werden, die von verschiedenen Plattformen gemeinsam genutzt werden.
HFS+
Der Volume-Header ist am Anfang einer HFS+-Partition vorhanden. Er enthält alle allgemeinen Informationen darüber sowie den Speicherort der primären Dateisystemstrukturen. Eine identische Kopie des Volume-Headers wird am Ende der Partition platziert.
Der Rest der Dateisystemmetadaten wird durch eine Reihe spezieller Dateien dargestellt, die an einer beliebigen Stelle innerhalb der Partition gespeichert werden können. Die meisten von ihnen werden als B-Bäume organisiert. Ein einzelner B-Baum besteht aus einigen Knoten, von denen jeder Datensätze mit einem Schlüssel und spezifischen Daten enthält.
HFS+ unterteilt den gesamten Speicherplatz in gleich große Einheiten, sogenannte Zuordnungsblöcke (Allocation Blocks). Um die Fragmentierung zu reduzieren, werden diese Blöcke normalerweise in kontinuierlichen Gruppen, sogenannten Klumpen (Clumps), zugeordnet. In der Zuordnungsdatei wird aufgezeichnet, ob jeder Zuordnungsblock gerade belegt ist.
Die Informationen über den Inhalt jeder Datei werden mithilfe spezieller Fork-Strukturen verwaltet – eine für die eigentlichen Daten (Data Fork) und eine für unterstützende Informationen (Ressource Fork). Ein zusammenhängender Bereich von Zuordnungsblöcken, die einer Verzweigung zugewiesen sind, wird als Extent bezeichnet. Ein einzelner Extent wird durch die Nummer seines Startblocks und die Länge in Blöcken dargestellt.
Die Katalogdatei (Catalog File) beschreibt die Hierarchie aller Dateien und Ordner sowie deren wichtige Eigenschaften, wie z. B. Namen. Außerdem werden die ersten acht Extents jeder Fork beibehalten. Weitere Extents finden Sie in der Extents-Überlaufdatei (Extents Overflow File). Andere Dateieigenschaften sind in der Attributdatei (Attributes File) enthalten.
Darüber hinaus unterstützt HFS+ Hardlinks – mehrere Verweise auf eine einzelne Instanz des Inhalts einer Datei. Ein solcher Referenz ist nichts anderes als eine separate Hardlink-Datei, die in der Katalogdatei für jeden Verzeichniseintrag erstellt wird. In der Zwischenzeit wird der ursprüngliche Inhalt in das versteckte Stammverzeichnis verschoben.
Alle Änderungen am Dateisystem werden im Journal dokumentiert. Die Größe des Journals in HFS+ ist begrenzt – neue Informationen werden jedes Mal hinzugefügt und über die alten Journaleinträge geschrieben. Auf diese Weise überschreibt HFS+ ältere Informationen, um das Journal für die Aufzeichnungen über neuere Änderungen freizugeben.
Auf dem Bild unten sehen Sie die Beziehung zwischen den Schlüsselelementen der HFS+-Struktur – dem Volume-Header, dem Journal und der Katalogdatei:

Löschung
Prozedur: HFS+ aktualisiert die Katalogdatei durch Neuorganisation des B-Baums, wodurch möglicherweise die Datensätze in dem Knoten, der der gelöschten Datei entspricht, überschrieben werden. Die entsprechenden Blöcke in der Zuordnungsdatei werden als frei markiert. Der Hardlink wird aus dem Verzeichniseintrag gelöscht. Die Data-Fork-Extents verbleiben jedoch im Volumen. Außerdem werden diese Informationen für eine Weile in den Journalaufzeichnungen gespeichert.
Wiederherstellung: Mithilfe des Journals kann man möglicherweise die Datensätze, die den vorherigen Status der aktualisierten Blöcke beschreiben, finden und die Metadaten der kürzlich gelöschten Elemente identifizieren. Die Wahrscheinlichkeit der Datenrettung hängt stark davon ab, wie lange das System nach dem Löschen aktiv war. Wenn diese Journaleinträge jedoch zerstört wurden, kann die RAW-Wiederherstellungsmethode hervorragende Ergebnisse für nicht fragmentierte Dateien liefern. Dennoch stellen die verbleibenden fragmentierten Dateien ein Problem dar und führen zu einer unvollständigen Datenrettung.
Formatierung
Prozedur: Die Katalogdatei wird auf die Standardhierarchie zurückgesetzt und verliert daher alle Datensätze zu vorherigen Dateien. Andererseits bleiben das Journal und der Dateninhalt selbst erhalten.
Wiederherstellung: Ein Datenrettungsprogramm kann das Journal ansprechen, um alles abzurufen, was aus seinen Datensätzen wiedererlangt werden kann, und dann die RAW-Wiederherstellungsmethode verwenden, um die fehlenden Dateien mithilfe vordefinierter Vorlagen wiederherzustellen. Ebenso sind die Datenrettungsaussichten bei starker Fragmentierung gering.
APFS
APFS setzt eine völlig andere Strategie für die Datenorganisation ein. Ein APFS-Volumen befindet sich immer in einem speziellen Container. Ein einzelner Container kann mehrere Volumen (Dateisysteme) umfassen, die sich den verfügbaren Speicherplatz teilen. Mithilfe der gängigen Bitmap-Strukturen werden alle genutzten und freien Blöcke im Container erfasst. Mittlerweile verfügt jedes der Volumen über einen eigenen Superblock und verwaltet seine eigenen Elemente, die die Informationen speichern, wie z. B. Verzeichnishierarchie, Dateiinhalte und Metadaten.
Die Zuordnung von Dateien und Ordnern wird als B-Baum dargestellt. Er hat die gleichen Funktionen wie die Katalogdatei in HFS+. Jedes darin enthaltene Element besteht aus mehreren Datensätzen, und jeder Datensatz wird als Schlüssel und Wert gespeichert.
Der Inhalt einer Datei besteht aus mindestens einem Extent. Ein Extent enthält Informationen darüber, wo der Inhalt beginnt und wie lang er in Blöcken ist. Für alle Extents im Volumen existiert ein separater B-Baum.
Im Gegensatz zu HFS+ ändert APFS niemals vorhandene Objekte. Stattdessen erstellt es ihre Kopien und führt die notwendigen Änderungen an einem neuen Speicherort auf dem Speicher durch – das Prinzip, das als Copy-on-Write (CoW) bekannt ist.
Löschung
Prozedur: APFS wischt die entsprechenden Knoten im B-Baum der Datei- und Ordnerzuordnung ab.
Wiederherstellung: Möglicherweise können ältere Versionen der fehlenden Knoten gefunden und analysiert werden, um ihre aktuellsten Instanzen zu rekonstruieren. APFS integriert jedoch die Verschlüsselung tief in sein Design, die auf Apple-Geräten üblicherweise standardmäßig aktiviert ist. Wenn die Verschlüsselung aktiv ist, werden nicht nur die Benutzerdaten, sondern auch wichtige Metadatenstrukturen geschützt, was den Wiederherstellungsprozess erheblich erschwert.
Die Dateisysteme von Linux
Linux ist im Gegensatz zu Windows und macOS ein Open-Source-Projekt, das von einer Community von Enthusiasten entwickelt wird. Deshalb bietet es so viele Dateisystemvarianten zur Auswahl: Ext2, Ext3, Ext4, ReiserFS, XFS, JFS, Btrfs und F2FS.
Ext2
Alle Parameter dieses Dateisystems befinden sich in dem Superblock.
Ext2 unterteilt den Speicherplatz in kleine Einheiten, sogenannte Blöcke. Die Blöcke werden dann in größeren Einheiten, sogenannten Blockgruppen (Block Groups), angeordnet. Die Informationen zu allen Blockgruppen sind in der Deskriptortabelle (Descriptor Table) verfügbar, die unmittelbar nach dem Superblock gespeichert wird. Jede Blockgruppe enthält außerdem die Block-Bitmap und die Inode-Bitmap, um den Status ihrer Blöcke und Inodes zu verfolgen.
Der Inode ist ein Kernkonzept für Ext2. Er wird verwendet, um jede Datei und jeden Ordner im Dateisystem zu beschreiben, einschließlich ihrer Größe und der Position der Blöcke, die die tatsächlichen Daten enthalten. Die Inodes für jede Blockgruppe werden in ihrer Inode-Tabelle gespeichert.
Der Name gilt jedoch nicht als Metadaten gemäß diesem Dateisystem. Namen werden zusammen mit den entsprechenden Inode-Nummern separat in speziellen Verzeichnisdateien gespeichert.
Auf dem Bild unten sehen Sie die Beziehung zwischen den Schlüsselelementen der Ext2-Struktur – dem Superblock, Blockgruppen, Inode-Tabellen, Inodes:

Löschung
Prozedur: Ext2 kennzeichnet den Inode, der die Datei beschreibt, als frei und aktualisiert die Block- und die Inode-Bitmaps. Der Datensatz, der den Dateinamen mit einer bestimmten Inode-Nummer verknüpft, wird aus der Verzeichnisdatei entfernt.
Wiederherstellung: Mithilfe der im Inode verbleibenden Informationen sind die Chancen, die Datei abzurufen, recht hoch. Da der Name jedoch nicht im Inode gespeichert wird und der Link dazu nicht mehr besteht, geht er wahrscheinlich dauerhaft verloren.
Formatierung
Prozedur: Ext2 räumt die vorhandenen Blockgruppen auf und löscht die Inodes.
Wiederherstellung: Mit der RAW-Wiederherstellungsmethode können Dateien anhand ihres bekannten Inhalts wiedererlangt werden. Die Datenrettungschancen hängen stark vom Grad der Fragmentierung ab: Fragmentierte Dateien werden wahrscheinlich beschädigt.
Ext3/Ext4
Der Hauptvorteil von Ext3 gegenüber Ext2 besteht darin, dass es Journaling hinzufügt. Das Journal ist als spezielle Datei implementiert, die alle Änderungen am Dateisystem protokolliert.
Ext4 ist das Ergebnis der Erweiterung von Ext3 um neue Dateisystemstrukturen. Die markanteste davon wird als Extent bezeichnet. Anstatt den Inhalt auf einzelne Blöcke aufzuteilen, versucht Ext4, möglichst viele Daten in einem zusammenhängenden Bereich unterzubringen. Dieser Bereich wird durch die Adresse seines Startblocks und seine Länge in Blöcken beschrieben. Solche Extents können direkt im Inode gespeichert werden. Wenn eine Datei jedoch mehr als vier Extents hat, werden die restlichen als B+-Baum angeordnet.
Ext4 setzt außerdem verzögerte Zuweisung ein – es sammelt Daten, die in den Speicher geschrieben werden müssen, bevor ihnen tatsächlicher Speicherplatz zugewiesen wird, und hält so die Fragmentierung auf ein Minimum.
Auf dem Bild unten sehen Sie die Beziehung zwischen den Schlüsselelementen der Ext3/Ext4-Struktur – dem Superblock, dem Journal, Blockgruppen, Inode-Tabellen, Inodes:

Löschung
Prozedur: Das Dateisystem erstellt einen Eintrag im Journal und löscht dann den zugehörigen Inode. Der Verzeichniseintrag wird nicht vollständig gelöscht, sondern die Reihenfolge beim Lesen des Verzeichnisses wird geändert.
Wiederherstellung: Mithilfe der Journaleinträge ist die Wiederherstellung gelöschter Dateien auch mit den ursprünglichen Namen möglich. Dennoch hängt die Qualität des Datenrettungsergebnisses von der Zeit ab, die das Dateisystem nach dem Löschen in Betrieb bleibt.
Formatierung
Prozedur: Alle Blockgruppen sowie Datei-Inodes und sogar das Journal werden ausgeräumt. Trotzdem enthält das Journal möglicherweise immer noch Informationen zu einigen der kürzlich erstellten Dateien.
Wiederherstellung: Die Wiedergewinnung verlorener Dateien ist nur mithilfe der RAW-Wiederherstellungsmethode möglich. Dennoch ist die Wahrscheinlichkeit sehr gering, wenn sie fragmentiert sind.
ReiserFS
Eine ReiserFS-Partition wird in Blöcke fester Größe unterteilt. Die wichtigsten Informationen dazu gibt es im Superblock. Direkt im Anschluss an den Superblock befindet sich eine Bitmap der genutzten und freien Blöcke.
Das Dateisystem basiert vollständig auf einer Struktur namens S+Baum, die aus internen Knoten und Blattknoten besteht. Dieser Baum dient der Organisation aller Dateien, Ordner und Metadaten. Es gibt vier Grundtypen von Elementen in diesem Baum: indirekte Elemente, direkte Elemente, Verzeichniselemente und Statistikelemente. Direkte Elemente enthalten die tatsächlichen Daten, während indirekte Elemente nur auf bestimmte Datenblöcke verweisen. Verzeichniselemente stellen Einträge in einem Verzeichnis dar und Statistikelemente enthalten Details zu Dateien und Ordnern. Jedem Element wird ein eindeutiger Schlüssel zugewiesen, mit dem es im Baum gefunden werden kann. Der Schlüssel enthält seine Kennung, Adresse und den Elementtyp.
ReiserFS wendet einen speziellen Mechanismus namens Tail-Packing an. Er kombiniert Dateien und Dateifragmente, die kleiner als ein vollständiger Block sind, und speichert sie direkt in den Blattknoten des S+-Baums. Solcher Ansatz verringert die Menge an verschwendetem Platz und den Grad der Fragmentierung.
Das Journal dokumentiert alle am Dateisystem vorgenommenen Änderungen. Anstatt die Veränderungen direkt im S+Baum vorzunehmen, schreibt ReiserFS sie zuerst in das Journal. Zu einem späteren Zeitpunkt werden sie aus dem Journal an einen tatsächlichen Speicherort auf dem Speicher kopiert. Somit kann ReiserFS viele Metadatenkopien speichern.
Auf dem Bild unten sehen Sie die Beziehung zwischen den Schlüsselelementen der ReiserFS-Struktur – dem Superblock, dem S+Baum und Baum-Elementen:

Löschung
Prozedur: ReiserFS aktualisiert den S+Baum, um die Datei auszuschließen und ändert den Status der jeweiligen Blöcke in der Bitmap.
Wiederherstellung: Da die Kopie des S+-Baums erhalten bleibt, ist es möglich, alle Dateien, einschließlich ihrer Namen, wiederherzustellen. Darüber hinaus kann die vorherige Version einer Datei aus einer älteren Kopie des S+Baums abgerufen werden.
Formatierung
Prozedur: ReiserFS erstellt einen neuen S+-Baum über dem vorhandenen.
Wiederherstellung: Der vorherige S+-Baum kann aus einer Kopie wiederhergestellt werden, was die vollständige Datenrettung ermöglicht. Die Wahrscheinlichkeit sinkt jedoch, wenn die Partition voll ist. In solcher Situation schreibt das Dateisystem möglicherweise neue Informationen über die alten Daten.
XFS
XFS besteht aus gleich großen Regionen, die Zuordnungsgruppen (Allocation Groups) genannt werden. Jede Zuordnungsgruppe verhält sich wie ein einzelnes Dateisystem, das über einen eigenen Superblock verfügt und seine eigenen Strukturen und Speicherplatznutzung beibehält.
Der freie Raum wird mithilfe eines Paares von B+-Bäumen verfolgt: Der erste gibt den Startblock der zusammenhängenden Freiraumregion an und der zweite die Anzahl der darin enthaltenen Blöcke. Ein ähnlicher bereichsbasierter Ansatz wird zum Verfolgen der Datei zugewiesenen Blöcke benutzt.
Alle Dateien und Ordner in XFS werden durch spezielle Inode-Strukturen dargestellt, die ihre Metadaten enthalten. Wenn möglich, wird die Zuweisung der Extents direkt im Inode gespeichert. Bei sehr großen oder fragmentierten Dateien werden die Extents von einem anderen B+-Baum verfolgt, der mit dem Inode verknüpft ist. In jeder Zuordnungsgruppe wird ein separater B+-Baum verwendet, um diese Inodes bei der Zuweisung und Freigabe aufzuzeichnen.
Wie viele ähnliche Dateisysteme speichert XFS den Dateinamen nicht im Inode. Der Name existiert nur im Verzeichniseintrag.
XFS implementiert Journaling für Vorgänge mit Metadaten. Das Journal speichert Änderungen, bis die tatsächlichen Aktualisierungen festgeschrieben werden.
Auf dem Bild unten sehen Sie die Beziehung zwischen den Schlüsselelementen der XFS-Struktur – Zuordnungsgruppen, Superblocks, B+Baum-Strukturen, Inodes:

Löschung
Prozedur: Der für die Datei verantwortliche Inode wird aus dem B+Baum ausgeschlossen; die meisten darin enthaltenen Informationen werden überschrieben, die Anfangsdaten bleiben jedoch erhalten. Der Bezug zwischen Verzeichniseintrag und Dateiname geht verloren.
Wiederherstellung: XFS speichert Kopien der Metadaten im Journal und ermöglicht so erfolgreiche Wiederherstellung verlorener Dateien. Die Chancen, sie zurückzubringen, sind recht hoch, selbst mit korrekten Namen.
Formatierung
Prozedur: Die B+Bäume, die die Speicherplatzzuweisung verwalten, werden gelöscht und ein neues Stammverzeichnis überschreibt das vorhandene.
Wiederherstellung: Die Chancen, Dateien wiederherzustellen, die sich nicht am Anfang des Speichers befanden, sind hoch, im Gegensatz zu Dateien, die näher am Anfang gespeichert waren.
JFS
Die wesentlichen Informationen zu JFS sind im Superblock enthalten.
Ein JFS-Volumen kann aus mehreren Regionen bestehen, die als Zuordnungsgruppen (Allocation Groups) bezeichnet werden. Jede Zuordnungsgruppe verfügt über ein oder mehrere Dateisätze (FileSets).
Jede Datei und jeder Ordner im Dateisystem wird durch ihren Inode beschrieben. Der Inode enthält nicht nur die identifizierenden Informationen, sondern verweist auch auf den Speicherort, an dem der Inhalt der Datei gespeichert ist. Der Inhalt selbst wird durch einen oder mehrere Extents dargestellt. Ein Extent besteht aus einem oder mehreren zusammenhängenden Blöcken. Alle Extents werden mithilfe eines speziellen B+-Baums indiziert.
Der Inhalt kleiner Verzeichnisse wird in ihren Inodes gespeichert, während größere Verzeichnisse als B+-Bäume organisiert werden.
Der freie Speicherplatz in JFS wird auch mithilfe von B+Bäumen verfolgt: Ein Baum wird für die Startblöcke freier Extents verbraucht, und der zweite Baum zeichnet die Anzahl freier Extents auf.
JFS verfügt über einen dedizierten Protokollbereich und schreibt jedes Mal in das Journal, wenn eine Metadatenänderung auftritt.
Auf dem Bild unten sehen Sie die Beziehung zwischen den Schlüsselelementen der JFS-Struktur – dem Superblock, Zuordnungsgruppen, Dateisätzen, B+-Bäumen, Journal, Inodes:

Löschung
Prozedur: JFS aktualisiert den B+-Baum des freien Speicherplatzes und gibt den mit der Datei verknüpften Inode frei. Das Verzeichnis wird neu erstellt, um die Änderungen widerzuspiegeln.
Wiederherstellung: Der Inode verbleibt auf dem Speicher, wodurch sich die Wahrscheinlichkeit der Datenrettung auf fast 100 % erhöht. Lediglich bei Dateinamen sind die Wiederherstellungschancen gering.
Formatierung
Prozedur: JFS erstellt einen neuen B+-Baum. Er ist von Anfang an klein und wird mit der weiteren Nutzung des Dateisystems erweitert.
Wiederherstellung: Die Chancen, verlorene Dateien nach der Formatierung wiederherzustellen, sind angesichts der geringen Größe des neuen B+-Baums recht hoch.
Btrfs
Wie viele andere Dateisysteme beginnt Btrfs mit dem Superblock, der die wesentlichen Informationen über sein Layout bereitstellt.
Andere Elemente werden als B-Bäume dargestellt, von denen jeder seinen eigenen Zweck hat. Der Standort des Root-B-Baums kann im Superblock gefunden werden, und dieser Baum wiederum enthält Verweise auf die übrigen B-Bäume. Jeder B-Baum besteht aus internen Knoten und Blättern: Ein interner Knoten ist mit einem untergeordneten Knoten oder Blatt verknüpft, während ein Blatt ein Element mit tatsächlichen Informationen enthält. Die genaue Struktur und der Inhalt eines Elements hängen vom Typ des jeweiligen B-Baums ab.
Eines der herausragenden Merkmale von Btrfs ist, dass es sich auf mehrere Geräte verteilen kann, deren Speicherplatz in einem einzigen gemeinsamen Pool zusammengefasst wird. Danach wird jedem Block des physischen Speichers eine virtuelle Adresse zugewiesen. Diese Adressen, nicht die echten, werden dann von anderen Dateisystemstrukturen benutzt. Die Informationen über die Korrespondenz zwischen der virtuellen und der physischen Adresse sind im Chunk-B-Baum verfügbar. Er weiß auch, welche Geräte den Pool bilden. Der Geräte-B-Baum ordnet umgekehrt die physischen Blöcke auf den zugrunde liegenden Geräten ihren virtuellen Adressen zu.
Der Dateisystem-B-Baum organisiert alle Informationen zu Dateien und Ordnern. Sehr kleine Dateien können direkt im Baum innerhalb von Extent-Elementen gespeichert werden. Größere Dateien werden außerhalb in zusammenhängenden Bereichen, sogenannten Extents, gespeichert. In diesem Fall verweist ein Extent-Element auf alle Extents, zu denen die Daten der eigentlichen Datei gehören. Verzeichniselemente bilden den Inhalt von Ordnern, sie enthalten auch Dateinamen und verweisen auf ihre Inode-Elemente. Inode-Elemente werden für andere Eigenschaften wie Größe, Berechtigungen usw. verwendet.
Der Extent-B-Baum verfolgt die zugewiesenen Extents in Extent-Elementen. Er verhält sich wie eine Karte des freien Raums.
In den beschriebenen B-Bäumen werden Änderungen niemals vor Ort durchgeführt. Stattdessen werden die geänderten Informationen an einen anderen Ort geschrieben. Diese Technik ist als Copy-on-Write bekannt.
Auf Solid-State-Laufwerken kann Btrfs jedoch als ungenutzt markierte Extents erkennen und sie automatisch löschen, indem es den TRIM-Befehl durchführt.
Löschung
Prozedur: Btrfs baut den Dateisystem-B-Baum neu auf, um die mit der Datei verknüpften Knoten auszuschließen, und gibt die ihm zugewiesenen Extents im Extent-B-Baum frei. Alle verknüpften Strukturen werden aktualisiert.
Wiederherstellung: Die notwendigen Elemente sind nicht mehr Teil der Dateisystemstruktur. Da Brtfs jedoch auf dem Copy-on-Write-Prinzip basiert, ist es möglich, auf die älteren Kopien, einschließlich der vorherigen Version des Dateisystem-B-Baums, zuzugreifen, sie zu analysieren und die gelöschte Datei erfolgreich wiederherzustellen, vorausgesetzt, ihr Inhalt und ihre Metadaten sind vorhanden und wurden nicht überschrieben.
F2FS
F2FS wurde unter Berücksichtigung der Besonderheiten von Flash-Speicher entwickelt. Es unterteilt den gesamten Raum in Segmente fester Größe. Ein Abschnitt besteht aus aufeinanderfolgenden Segmenten, und eine Reihe von Abschnitten bildet eine Zone.
Der Superblock befindet sich am Anfang einer F2FS-Partition. Er enthält die grundlegenden Informationen darüber und den Standort anderer wichtiger Bereiche. Zu Sicherungszwecken gibt es eine zweite Kopie des Superblocks. Die Checkpoint-Blöcke speichern Wiederherstellungspunkte für den alten und aktuellen Zustand wichtiger Dateisystemelemente.
Die Platzierung der Daten wird über spezielle Knotenstrukturen verwaltet. Es gibt drei Arten dieser Knoten: direkte Knoten, indirekte Knoten und Inodes. Ein direkter Knoten speichert die Adresse tatsächlicher Datenblöcke, ein indirekter Knoten verknüpft sich mit Blöcken in anderen Knoten und ein Inode enthält Metadaten, einschließlich des Dateinamens, der Größe und anderer Eigenschaften. Die Zuordnung von Knoten zu ihren physischen Standorten im Dateisystem wird in der Knotenadresstabelle (Node Address Table oder NAT) gespeichert.
Der Inhalt von Dateien und Ordnern wird im Hauptbereich (Main Area) gespeichert. Die darin enthaltenen Abschnitte trennen die Blöcke, die Daten enthalten, von den Knotenblöcken mit Indexinformationen. Der Nutzungsstatus aller Blocktypen wird in der Segmentinformationstabelle (Segment Information Table oder SIT) angezeigt – diejenigen, die benutzt werden, werden als gültig gekennzeichnet und diejenigen, die gelöschte Daten enthalten, gelten als ungültig. Der Segmentzusammenfassungsbereich (Segment Summary Area oder SSA) zeichnet auf, welche Blöcke zu welchem Knoten gehören.
Verzeichniseinträge in F2FS werden Dentries genannt. Ein Dentry enthält den Namen der Datei und ihre Inode-Nummer.
F2FS führt die Bereinigung durch, wenn nicht genügend freie Segmente vorhanden sind, und im Hintergrund, wenn das System inaktiv ist. Die Opfersegmente werden in diesem Fall anhand der Anzahl der verwendeten Blöcke entsprechend der SIT oder anhand ihres Alters ausgewählt.
Löschung
Prozedur: Die Änderungen werden an der Knotenadresstabelle (NAT) und Segmentinformationstabelle (SIT) vorgenommen. Diese Informationen werden im Speicher gehalten, solange ein neuer Checkpoint erstellt und in den Checkpoint-Block geschrieben wird. Der Inhalt der freigesetzten Blöcke bleibt erhalten, bis er während der Reinigung abgewischt wird.
Wiederherstellung: Mithilfe des aktuellen Checkpoints ist es möglich, auf den vorherigen Status der Dateisystem-Metadaten zuzugreifen und die mit der Datei verknüpften Knoten- und Datenblöcke zu lokalisieren, sofern sie nicht überschrieben wurden.
Die Dateisysteme von BSD, Solaris, Unix
Diese Unix-ähnlichen Betriebssysteme bieten zwei native Formate – UFS, das es schon seit den Anfängen gibt, und das moderne ZFS-Dateisystem.
UFS
Ein UFS-Volumen besteht aus einer oder mehreren Zylindergruppen (Cylinder Groups). Ihre Speicherorte und andere wichtige Details zum Dateisystem sind im Superblock verfügbar. In jeder Zylindergruppe wird außerdem eine Sicherungskopie des Superblocks gespeichert.
Jede Datei in UFS besteht aus einem Inode und Datenblöcken, die ihren eigentlichen Inhalt haben. Ein Inode enthält alle Eigenschaften der Datei, mit Ausnahme ihres Namens, der in einem Verzeichnis gespeichert wird. Er verweist auch direkt auf die Datenblöcke der ersten 12 Dateien. Wenn die Datei größer ist, verweist die nächste Adresse stattdessen auf indirekte Blöcke, die direkte Blockadressen enthalten.
Verzeichnisse in UFS werden durch Gruppen von Einträgen dargestellt, die eine Liste von Dateinamen und die Inode-Nummer jeder Datei speichern. Obwohl eine Datei immer einem einzelnen Inode zugeordnet ist, kann dieselbe Datei bei Hardlinks mehrere Namen haben. Wenn Dateinamen in verschiedenen Verzeichnissen auf denselben Inode verweisen, wird die Anzahl der Referenzen im Inode angezeigt.
Jede Zylindergruppe behält ihre eigenen Bitmaps freier Blöcke und freier Inodes. Überdies gibt es eine bestimmte Anzahl von Inodes, die jeweils Dateiattribute enthalten. Der Rest der Zylindergruppe wird mit Datenblöcken belegt.
Löschung
Prozedur: UFS löscht den zur Datei gehörenden Inode aus und aktualisiert die Bitmaps freier Blöcke und freier Inodes. Der entsprechende Eintrag wird aus dem Verzeichnis entfernt.
Wiederherstellung: Ohne den Inode gibt es keine Informationen über die Größe der Datei und die ersten 12 Datenblöcke. Auch die Verbindung zu ihrem Namen geht dauerhaft verloren. Die Daten können mit der RAW-Wiederherstellungsmethode wiedergewonnen werden. Bei fragmentierten Dateien sind die Chancen jedoch recht gering.
ZFS
Im Gegensatz zu den meisten Dateisystemen kann ZFS eine Reihe physischer Laufwerke umfassen, die in einem gemeinsamen Speicherpool zusammengefasst werden. Ein Pool enthält ein oder mehrere virtuelle Geräte, sogenannte Vdevs. Ein Vdev verfügt über eine Bezeichnung, die es beschreibt, wobei aus Sicherheitsgründen vier Kopien gespeichert werden. In jedem Vdev-Label befindet sich ein Uberblock. Ähnlich wie der Superblock, der von anderen Dateisystemtypen verwendet wird, enthält er wichtige Informationen, die für den Zugriff auf den gesamten Inhalt erforderlich sind.
Der Speicherplatz wird von ZFS in Einheiten variabler Größe, sogenannten Blöcken, zugewiesen. Alle Blöcke in ZFS werden als Objekte unterschiedlichen Typs organisiert. Objekte zeichnen sich durch spezielle Strukturen aus, die als Dnodes bezeichnet werden. Ein Dnode beschreibt den Objekttyp und die Größe sowie die Sammlung von Blöcken, aus denen seine Daten bestehen. Er kann bis zu drei Blockzeiger enthalten. Ein Blockzeiger ist die Grundstruktur, die ZFS zur Blockadressierung verwendet. Er kann entweder auf einen Blattblock zeigen, der tatsächliche Informationen enthält, oder auf einen indirekten Block, der auf einen anderen Block zeigt.
Die zugehörigen Objekte werden weiter in Objektsätze gruppiert. Jedes darin enthaltene Objekt wird durch eine Objektnummer eindeutig identifiziert. Ein Beispiel für einen Objektsatz ist ein Dateisystem, das Dateiobjekte und Verzeichnisobjekte enthält. Die Sammlung von Knoten, die die Objekte in dem angegebenen Objektsatz beschreiben, wird auch als Objekt gespeichert, auf das der Metaknoten zeigt. Die Metadaten, die sich auf den gesamten Pool beziehen, sind auch in einem Objektsatz namens Metaobjektsatz (Meta Object Set oder MOS) enthalten.
Wenn ZFS Daten in den Speicher schreibt, werden die Blöcke niemals an Ort und Stelle überschrieben. Zunächst wird ein neuer Block einer anderen Stelle zugewiesen. Sobald der Vorgang abgeschlossen ist, werden die Dateisystemmetadaten aktualisiert, um auf den neu geschriebenen Block zu verweisen, während auch die ältere Version erhalten bleibt.
Löschung
Prozedur: ZFS trennt die Datenblöcke des Dateiobjekts und den jeweiligen Dnode. Die Objektnummer steht zur Wiederverwendung zur Verfügung. Die Datei wird aus der Liste im Verzeichnisobjekt entfernt. Der Uberblock wird durch einen neuen Uberblock ersetzt.
Wiederherstellung: Da ZFS die On-Copy-on-Write-Technik verwendet, können alte Kopien im Speicherpool verbleiben, was die erfolgreiche Wiederherstellung gelöschter Dateien ermöglicht. Da die Daten jedoch in Blöcken unterschiedlicher Größe über die Laufwerke verteilt sind, kann der Vorgang nicht ohne intakte Pool-Metadaten durchgeführt werden, die für die korrekte Neuzusammensetzung seiner Konfiguration notwendig sind.
Wie sich TRIM auf die Chancen der Datenwiederherstellung auswirkt
Die meisten modernen SSDs und viele neuere SMR-Festplatten nutzen eine interne Übersetzungsschicht, die den TRIM-Befehl unterstützt. Wenn TRIM aktiviert ist, ermöglicht es dem Dateisystem, dem Laufwerk mitzuteilen, dass bestimmte Blöcke nicht mehr verwendet werden. Diese Blöcke werden dann als frei markiert und für die automatische Datenbereinigung (Garbage Collection) eingeplant, einem Prozess, der die Daten physisch löscht. Dieser Ansatz trägt zwar zur Leistungssteigerung und Verlängerung der Lebensdauer des Laufwerks bei, macht aber die Wiederherstellung gelöschter oder formatierter Dateien extrem schwierig, in den meisten Fällen praktisch unmöglich.
Sobald TRIM ausgeführt wurde, behandelt das Laufwerk die betroffenen Blöcke als leer. Selbst wenn die Daten noch nicht physisch gelöscht wurden, werden alle Verweise darauf auf der internen Zuordnungsebene des Laufwerks entfernt. Dadurch werden die Dateien sowohl für das Betriebssystem als auch für Datenrettungssoftware unsichtbar. Wenn die Speicherbereinigung schließlich ausgeführt wird, werden die Daten endgültig zerstört und können nicht wiederhergestellt werden.
Die Speicherbereinigung erfolgt nicht immer sofort. Der Zeitpunkt hängt vom Laufwerksmodell, dem Speichertyp und der Arbeitslast ab. Sie kann innerhalb von Sekunden, Stunden oder sogar Tagen erfolgen. Allerdings wird die interne Zuordnung nahezu sofort aktualisiert, und das Laufwerk gibt beim Lesen der beschnittenen Bereiche typischerweise Nullen zurück, noch bevor die Daten physisch gelöscht werden.
Löschung
Prozedur: Das Dateisystem kennzeichnet den belegten Speicherplatz als zur Wiederverwendung verfügbar und gibt kurz darauf einen TRIM-Befehl aus. Das Laufwerk aktualisiert seine interne Zuordnung, um anzuzeigen, dass die entsprechenden Blöcke nicht mehr verwendet werden, und plant sie zur Speicherbereinigung ein. Das eigentliche Abwischen kann sofort erfolgen oder verzögert sein, von wenigen Sekunden bis zu mehreren Tagen.
Wiederherstellung: Es gibt in der Regel nur ein sehr kurzes Zeitfenster (oft nur wenige Sekunden), in dem das Trennen des Laufwerks verhindern kann, dass der Übersetzer aktualisiert wird. Sobald TRIM ausgeführt wurde, kann die Datenwiederherstellungssoftware nicht mehr auf die Daten zugreifen. In seltenen Fällen können Datenrettungsexperten möglicherweise noch Spezialgeräte einsetzen, die die Übersetzungsschicht des Laufwerks umgehen und die Rohdaten der Speicherchips direkt auslesen. Der Erfolg ist jedoch höchst ungewiss und hängt von vielen technischen Faktoren ab. Wenn das Laufwerk eingeschaltet bleibt, werden die Daten durch die automatische Speicherbereinigung schließlich vollständig gelöscht.
Formatierung
Prozedur: Die Dateisystemstrukturen werden zurückgesetzt, und TRIM wird typischerweise für alle Blöcke ausgegeben, die zuvor in Gebrauch waren. Das Laufwerk aktualisiert entsprechend seine interne Zuordnung und markiert diese Blöcke als frei. Die Speicherbereinigung kann sofort beginnen oder verzögert werden, abhängig vom internen Zustand und der Auslastung des Laufwerks.
Wiederherstellung: Wie beim Löschen von Dateien besteht auch hier die Möglichkeit, das Laufwerk vor Beginn der Speicherbereinigung auszuschalten, wodurch unter Umständen eine professionelle Wiederherstellung der Rohdaten möglich ist. Sobald die Speicherbereinigung die Blöcke gelöscht hat, sind die Daten endgültig verloren.
Metadatenbeschädigung
Prozedur: Wenn die Metadaten des Dateisystems beschädigt sind, kann das Betriebssystem bestimmte Blöcke möglicherweise nicht mehr verfolgen und gibt daher keinen TRIM-Befehl mehr für diese Blöcke aus. Ohne diesen Befehl aktualisiert das Laufwerk den Status der betroffenen Blöcke nicht, und sie werden nicht zur Speicherbereinigung eingeplant.
Wiederherstellung: Da TRIM nicht ausgelöst wird, bleiben die Daten in diesen Blöcken oft unberührt, obwohl sie über das Betriebssystem nicht mehr zugänglich sind. In solchen Fällen kann eine Datenwiederherstellungssoftware die verlorenen Dateien möglicherweise finden und wiederherstellen, wobei die Erfolgsaussichten vom Ausmaß der Beschädigung und dem jeweiligen Dateisystemtyp abhängen.
Abschließend lässt sich sagen, dass es zwar wichtig ist zu verstehen, wie Dateisysteme die Datenwiederherstellung beeinflussen, doch in vielen Fällen kann auch die Verfügbarkeit der richtigen Werkzeuge einen entscheidenden Unterschied machen. Um die Erfolgsaussichten zu maximieren, insbesondere bei komplexen oder ungewöhnlichen Dateisystemen, sollten Sie die Verwendung professioneller Datenrettungssoftware von SysDev Laboratories in Betracht ziehen. Diese Lösungen sind für die Arbeit mit verschiedenen Dateisystemen und Speicherkonfigurationen konzipiert und bieten Funktionen, die über das hinausgehen, was die meisten einfachen Wiederherstellungsprogramme leisten können.