How does a filesystem relate to the data recovery potential?
To start with, any usable storage device, from a tiny memory card to a bulky internal hard disk drive, contains one or several partitions. These are regions on the same physical medium that are created by the operating system and treated as separate logical disks. The information about them is usually stored at the drive’s beginning in a special element named a partition table.
Each partition is independent of the others and has its own filesystem (abbreviated to FS). This is the main mechanism responsible for data placement within the boundaries of a partition. Thanks to it, the data is kept arranged and can be easily accessed whenever this is necessary.
Yet, the filesystems are not all equal, they may have different principles of organizing the storage space. Distinct instances are mostly referred to as types, or, less frequently, as formats. The type may be chosen by the OS automatically or picked out by the user from the proposed options.
Each FS type separates the data comprising files from the information describing this content, known as metadata. The latter includes the file’s name, size, location, position in the directory structure and other properties that help to identify it. At the same time, the rules they follow to store those technical details may vary substantially.
Besides regulating the way information is allocated, the filesystem defines the method of handling it in the process of deletion or storage formatting. As a rule, the content of files is not destroyed right away, but the metadata is wiped or modified to emphasize that it’s now time to get rid of them. Therefore, in case of any mishaps and the need for recovery, the chances for success depend drastically on the behavior of the applied FS.
If you have deleted some data or the entire volume was formatted due to an unfortunate mistake, you can estimate the possibility to set things right if you know what type of filesystem actually performed this operation. Therefore, let’s have a closer look at different formats of Windows (NTFS, FAT/FAT32, exFAT, ReFS), macOS (HFS+, APFS), Linux (Ext2, Ext3, Ext4, ReiserFS, XFS, JFS) and BSD/Solaris/Unix (UFS, ZFS), their general structure as well as deletion and formatting practices.
The filesystems of Windows
Microsoft Windows currently offers two formats for its internal drives: NTFS and server-grade ReFS. External storage devices like USB sticks and memory cards usually employ FAT/FAT32 or exFAT.
NTFS
The beginning of an NTFS partition is occupied by the Volume Boot Record (VBR). This file contains the information related to the size and structure of the filesystem as well as the boot code.
NTFS manipulates data using the Master File Table (MFT). Basically, it is a database comprising records for every file and folder present in the FS. Each MFT record holds a variety of attributes like location, name, size, the date/time of creation and last modification. The MFT itself has the Bitmap attribute indicating which of the records are presently in use.
Very small files are stored as attributes immediately in the MFT cell. If the content is large, it will be saved outside the MFT, while the record will point to its location. Likewise, when the attributes cannot fit into a single MFT record, they are moved out of the table, and only their addresses are kept there.
Folders in NTFS are represented by directory entries. These, in fact, are files that contain a list of other files with references to them.
Another important file for NTFS is the Bitmap. It keeps track of all the taken and vacant locations in the filesystem.
In the picture below, you can see the relationship between the key elements of the NTFS structure – the Volume Boot Record ($Boot), Master File Table ($MFT) and the data content region:

Deletion
Procedure: NTFS keeps the MFT record for the file, but labels it as unused and marks the location occupied by its content as released in the Bitmap. The file is also removed from the directory entry.
Recovery: The file’s name, size and location should be left in the MFT record. If it remains unchanged and the data content has not been overwritten, the chances for recovery are 100%. If this record is missing, it may still be possible to find the file bypassing the FS structure with the help of the RAW-recovery method. In this case, the raw data on the drive is analyzed for the presence of pre-defined patterns that characterize files of the given type. Yet, the main drawback of this approach is the lack of the original names and folder structure in the results.
Formatting
Procedure: A new MFT is created, which wipes the beginning of the existing MFT. However, the rest of it remains untouched.
Recovery: The first 256 files are no longer represented in the MFT, thus, their retrieval is possible only with the RAW-recovery method. The recoverability of files that follow these 256 is up to 100%.
FAT/FAT32
The basic information about the FS organization in available in the Boot Sector at the very start of the partition.
FAT/FAT32 divides the storage space into identically sized pieces called clusters. The content of a file may take one or more clusters that are not necessarily close to each other. The files whose content is stored non-sequentially are referred to as fragmented.
The File Allocation Table (FAT) traces which clusters are used by which files. Two copies of the table are typically stored for backup purposes. Each cluster has its own entry in the FAT indicating whether it is occupied. If so, there will also be a link to the next cluster belonging to the very same file or a mark that this is the last cluster in the chain.
The Root Directory is a series of entries that describe all files and folders. Each directory entry comprises the file’s starting cluster, name, size and other attributes. The number of this cluster also points to an entry in the FAT table.
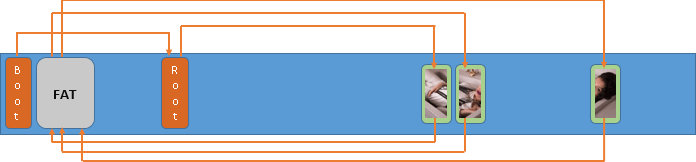
In the picture below, you can see the relationship between the key elements of the FAT/FAT32 structure – the Boot Sector, two FAT tables, Root Directory and the data area:

Deletion
Procedure: FAT/FAT32 marks the file’s directory entry as deleted and clears all the information contained in the corresponding FAT table entries, thus destroying the links to its intermediate and end clusters. The first character of the file’s name is replaced by a value signifying its deleted state. FAT32 also partially deletes the information about the starting cluster.
Recovery: The first cluster and the size can be found in the directory entry, but the location of the intermediate and end clusters has to be assumed. For this reason, data recovery may be incomplete. Besides, FAT/FAT32 doesn't perform defragmentation, making it difficult to restore files using the RAW-recovery method. Another issue is that file names are limited in length and can even be stored detached on the storage. Recovery of long names may bring no effect.
Formatting
Procedure: Both copies of the FAT table are cleared and the Root Directory is deleted. Yet, the data content is still there.
Recovery: Like in the previous scenario, consecutive files can be retrieved using the RAW-recovery method. However, due to the fragmentation problem, a large portion of the data may turn out to be corrupted.
exFAT
exFAT has been developed as the successor to FAT/FAT32, therefore, it closely resembles the filesystems of this family. The structure of an exFAT volume is likewise described in the Boot Sector. Another copy of the Boot Sector is stored for security purposes.
exFAT applies the File Allocation Table as well, yet, there is just one copy of it, and it contains links for fragmented files only. In addition, the status of clusters is not presented directly in the entry, it is managed with the help of a dedicated Allocation Bitmap. This bitmap is stored within the data region and shows whether the cluster is in use or ready to be written to. Such an approach makes it easier for exFAT to find contiguous clusters to place the file’s content, and, hence, to eliminate fragmentation.
Directory entries are handled the same way as in FAT/FAT32, but there is also a special entry in the Root Directory that keeps the information about the Allocation Bitmap.
In the picture below, you can see the relationship between the key elements of the exFAT structure – the Boot Sector, FAT table, Root Directory and the data area:
Deletion/Formatting
Procedure: exFAT changes the state of associated clusters in the Allocation Bitmap file. The FAT entries are not updated right away to avoid unnecessary writings. The data area is not wiped as well.
Recovery: If the file was fragmented, the chain of its clusters can be reconstructed using the remaining FAT entries. In case these links are lost, the recovery may be incomplete. Nevertheless, the RAW-recovery method may give positive results for exFAT thanks to lower fragmentation in comparison to FAT/FAT32.
ReFS
The layout of ReFS differs considerably from the rest of Microsoft Windows formats. The information within it is generally organized in the form of B+trees that work similarly to databases. B+trees are used for almost all elements in the filesystem, including the content of files and metadata. Such a tree is composed of the root, internal nodes and leaves. Each tree node has an ordered list of keys and pointers to the nodes of lower level or leaves.
The Directory is the main component of the FS. It is represented by a B+tree as well. The key in it corresponds to the number of a folder object. A file is not treated as a separate element of the Directory and exists in the form of a record.
Another notable feature of ReFS is its usage of Copy-on-Write (CoW) – the original FS entries are never modified right away, they are just copied and written to a new location along with the necessary changes.
Deletion
Procedure: The metadata structure should be rebuilt in response to the file’s deletion. However, ReFS doesn’t edit it right on the spot. Instead, it creates its copy, makes the required changes and links the data to the updated structure only after it is successfully written to the storage.
Recovery: Thanks to the Copy-on-Write method, the previous version of the metadata still remains on the storage, making it possible to recover up to 100% of the deleted files until they are overwritten with new data.
The filesystems of macOS
These days, Apple’s Disk Utility allows choosing from several FS types. HFS+ (also known as Mac OS Extended) was originally the default filesystem for macOS. However, starting with macOS High Sierra, Apple transitioned to the modern APFS filesystem designed and optimized for flash storage. The previously described exFAT format, though created by Microsoft, can also be applied on external devices that are shared between different platforms.
HFS+
The Volume Header is present at the start of an HFS+ partition. It provides all the general information about it as well as the location of the primary filesystem structures. An identical copy of the Volume Header is placed at the end of the partition.
The rest of the FS metadata is represented by a set of special files that can be stored anywhere within the partition. Most of them are organized as B-trees. A single B-tree consists of some nodes, each of them contains records holding a key and specific data.
HFS+ divides the entire storage space into equally sized units called allocation blocks. In an effort to reduce fragmentation, these blocks are usually allocated in continuous groups called clumps. The Allocation File records whether each allocation block is occupied at the moment.
The information about the content of each file is managed using special fork structures – one for the actual data (data fork) and one for supporting information (resource fork). A contiguous range of allocation blocks assigned to a fork is called an extent. A single extent is represented by the number of its starting block and length in blocks.
The Catalog File describes the hierarchy of all files and folders, as well as their vital properties, such as names. It also keeps the first eight extents of each fork. Additional extents can be found in the Extents Overflow File. Further file’s properties are contained in the Attributes File.
Furthermore, HFS+ supports hard links – multiple references to a single instance of a file’s content. Such a reference is nothing but a separate hard-link file created in the Catalog File for each directory entry. Meanwhile, the original content is moved to the hidden root directory.
All modifications to the FS are documented in the Journal. The Journal in HFS+ is limited in size – new information is added and written every time over the old journal records. This way, HFS+ overwrites older information to release the Journal for the records about newer modifications.
In the picture below, you can see the relationship between the key elements of the HFS+ structure – the Volume Header, Journal and the Catalog File:

Deletion
Procedure: HFS+ updates the Catalog File by reorganizing the B-tree, which may overwrite the records in the node that corresponds to the deleted file. The respective blocks in the Allocation File are marked as free. The hard link is deleted from the directory entry. However, the data fork extents remain in the volume. Also, this information is kept in the Journal records for a while.
Recovery: By referring to the Journal, it may be possible to find the records describing the previous state of the updated blocks and identify the metadata of the recently deleted items. Data recovery chances will depend greatly on how long the system has been active after deletion. Yet, if these Journal records have been wiped, the RAW-recovery method may give excellent results for non-fragmented files. Still and all, the remaining fragmented files will pose a problem and lead to incomplete recovery.
Formatting
Procedure: The Catalog File gets reset to the default hierarchy, therefore, it loses all the records about previous files. On the other hand, the Journal and the data content itself remain intact.
Recovery: A data recovery program can address the Journal to retrieve everything that is recoverable from its records, and then employ the RAW-recovery method to restore the missing files using pre-defined templates. Likewise, the chances for recovery will be low in case of extensive fragmentation.
APFS
APFS employs a totally different strategy for data organization. An APFS volume always resides within a special Container. A single Container can incorporate multiple volumes (filesystems) that share the available storage space. All used and free blocks in the Container are recorded with the help of the common Bitmap structures. Meanwhile, each of the volumes has its own Superblock and manages its own elements that store the information, such as directory hierarchy, file content and metadata.
The allocation of files and folders is presented as a B-tree. It has the same functions as the Catalog File in HFS+. Each item in it is made up of several records, and each record is stored as a key and value.
The content of a file consists of at least one extent. An extent carries the information about where the content starts and its length in blocks. A separate B-tree exists for all extents in the volume.
In contrast to HFS+, APFS never modifies any objects in place. Instead, it creates their copies and performs the necessary changes onto a new location on the storage – the principle known as Copy-on-Write (CoW).
Deletion
Procedure: APFS wipes the corresponding nodes in the files and folders allocation B-tree.
Recovery: It may be possible to find older versions of the missing nodes and analyze them to reconstruct their most recent instances. However, APFS integrates encryption deeply into its design, which is commonly enabled by default on Apple devices. When encryption is active, it safeguards not only user data but also essential metadata structures, significantly complicating the recovery process.
The filesystems of Linux
Linux, in contrast to Windows and macOS, is an open-source project developed by a community of enthusiasts. That is why if offers so many filesystem variations to choose from: Ext2, Ext3, Ext4, ReiserFS, XFS, JFS, Btrfs and F2FS.
Ext2
All the parameters of this FS can be found in the Superblock.
Ext2 divides storage space into small units called blocks. The blocks are then arranged into larger units called Block Groups. The information about all Block Groups is available in the Descriptor Table stored immediately after the Superblock. Each Block Group also contains the Block Bitmap and the Inode Bitmap to trace the state of their blocks and inodes.
The inode is a core concept for Ext2. It is used to describe every file and folder in the FS, including its size and location of the blocks that contain the actual data. The inodes for each Block Group are kept in its Inode Table.
However, the name is not considered to be metadata according to this FS. Names are stored separately in special directory files, along with the corresponding inode numbers.
In the picture below, you can see the relationship between the key elements of the Ext2 structure – the Superblock, Block Groups, Inode Tables, inodes:

Deletion
Procedure: Ext2 labels the inode describing the file as free and updates the Block and the Inode Bitmaps. The record associating the file’s name with a particular inode number is removed from the directory file.
Recovery: Using the information that remains in the inode, the chances to retrieve the file are quite high. However, since the name is not stored in the inode and the link to it no longer exists, it will probably get permanently lost.
Formatting
Procedure: Ext2 wipes the existing Block Groups and deletes the inodes.
Recovery: The RAW-recovery method can be applied to restore files by their known content. The chances for recovery depend heavily on the degree of fragmentation: fragmented files are likely to get corrupted.
Ext3/Ext4
The main benefit of Ext3 over Ext2 is that it adds journaling. The Journal is implemented as a special file that keeps track of all modifications to the filesystem.
Ext4 is the result of expanding Ext3 with new filesystem structures. The most distinctive of them is called an extent. Instead of allocating the content to individual blocks, Ext4 attempts to place as much data as possible to a continuous area. This area is described by the address of its starting block and its length in blocks. Such extents can be stored directly in the inode. Yet, when a file has more than four extents, the rest of them are arranged as a B+tree.
Ext4 also uses delayed allocation – it collects data that must be written to the storage before allocating actual space for it and thus keeps fragmentation at a minimum.
In the picture below, you can see the relationship between the key elements of the Ext3/Ext4 structure – the Superblock, Journal, Block Groups, Inode Tables, inodes:

Deletion
Procedure: The FS creates an entry in the Journal and then wipes the associated inode. The directory record is not deleted completely, and rather the order for directory reading gets changed.
Recovery: The retrieval of deleted files even with the initial names is possible by means of the Journal entries. Still, the quality of the recovery result depends on the amount of time the filesystem remains in operation after deletion.
Formatting
Procedure: All Block Groups as well as file inodes and even the Journal are cleared. Despite that, the Journal may still contain the information about some of the recently created files.
Recovery: The retrieval of lost files is possible only with the help of the RAW-recovery method. Still and all, the chances are very low in case they are fragmented.
ReiserFS
A ReiserFS partition is divided into blocks of a fixed size. The most important information about it is available in the Superblock. Directly following the Superblock there is a bitmap of used and free blocks.
The FS relies entirely on a structure called the S+tree, made up of internal and leaf nodes. Such a tree is used to organize all files, folders and metadata. There are four basic types of items in the tree: indirect items, direct items, directory items and stat items. Direct items contain the actual data, whereas indirect items just point to certain data blocks. Directory items represent entries in a directory, and stat items contain details about files and folders. Each item is assigned a unique key that can be used to locate them in the tree. The key contains its identifier, address and the item type.
ReiserFS applies a special mechanism called tail-packing. It combines files and file fragments that are smaller than a full block and stores them directly in the leaf nodes of the S+tree. Such an approach decreases the amount of wasted space and the degree of fragmentation.
The Journal documents all modifications made to the filesystem. Instead of performing the changes directly to the S+tree, ReiserFS writes them to the Journal first. At a later point, they are copied from the Journal to an actual location on the storage. Thus, ReiserFS can store lots of metadata copies.
In the picture below, you can see the relationship between the key elements of the ReiserFS structure – the Superblock, S+tree and tree items:

Deletion
Procedure: ReiserFS updates the S+tree to exclude the file and changes the status of the respective blocks in the bitmap.
Recovery: As the copy of the S+tree is preserved, it is possible to recover all files, including their names. Moreover, the previous version of a file can be retrieved from an older copy of the S+tree.
Formatting
Procedure: ReiserFS creates a new S+tree over the existing one.
Recovery: The previous S+tree can be retrieved from a copy, enabling complete data recovery. However, the chances go down in case the partition was full. In such a situation, the filesystem may write new information over the old data.
XFS
XFS is composed of equally sized regions called Allocation Groups. Each Allocation Group behaves like an individual filesystem that has its own Superblock, maintains its own structures and space usage.
Free space is traced using a pair of B+trees: the first one indicates the starting block of the contiguous free space region, and the second one – the count of blocks in it. A similar extent-based approach is used for tracking the blocks assigned to each file.
All files and folders in XFS are represented by special inode structures that hold their metadata. If possible, the allocation of extents is stored directly in the inode. For very large or fragmented files, extents are tracked by another B+tree linked to the inode. A separate B+tree is used in each Allocation Group to keep record of these inodes as they are allocated and freed.
Like many similar filesystems, XFS does not store the file name in the inode. The name exists only in the directory entry.
XFS implements journaling for operations with metadata. The Journal stores changes to it until the actual updates are committed.
In the picture below, you can see the relationship between the key elements of the XFS structure – Allocation Groups, Superblocks, B+tree structures, inodes:

Deletion
Procedure: The inode responsible for the file is excluded from the B+tree; most of the information in it gets overwritten, yet, the extent data remains intact. The reference between the directory entry and file’s name is lost.
Recovery: XFS keeps copies of metadata in the Journal, enabling successful recovery of lost files. The chances to bring them back are quite high, even with correct names.
Formatting
Procedure: The B+trees that manage space allocation are cleared, and a new root directory overwrites the existing one.
Recovery: The chances to recover files that were not located at the beginning of the storage are high, in contrast to files stored closer to the start.
JFS
The essential information about JFS is included in the Superblock.
A JFS volume can consist of multiple regions called Allocation Groups. Each allocation group has one or more FileSets.
Each file and folder in the filesystem is described by its inode. Besides holding the identifying information, the inode also points to the location where the file’s contents are stored. The content itself is represented by one or more extent. An extent is made up of one or several contiguous blocks. All extents are indexed using a special B+tree.
The content of small directories is stored within their inodes, while larger directories are organized as B+trees.
Free space in JFS is also traced using B+trees: one tree is used for the starting blocks of free extents, and the second tree records the number of free extents.
JFS has a dedicated log area and writes to the Journal every time a metadata change occurs.
In the picture below, you can see the relationship between the key elements of the JFS structure – the Superblock, Allocation Group, FileSet, B+trees, Journal, inodes:

Deletion
Procedure: JFS updates the B+tree of free space and releases the inode associated with the file. The directory is rebuilt to reflect the changes.
Recovery: The inode remains on the storage, increasing the chances of files recovery up to almost 100%. The recovery chances are low for file names only.
Formatting
Procedure: JFS creates a new B+tree. It is small from the beginning and gets extended with further filesystem use.
Recovery: The chances to recover lost files after formatting are quite high in view of the small size of the new B+tree.
Btrfs
Like many other filesystems, Btrfs starts with the Superblock, which provides the essential information about its layout.
Other elements are represented as B-trees, each having its own purpose. The location of the Root B-tree can be found in the Superblock, and this tree, in its turn, contains references to the rest of B-trees. Any B-tree consists of internal nodes and leaves: an internal node links to a child node or leaf, while a leaf holds some item with actual information. The exact structure and content of an item depends on the type of the given B-tree.
One of the prominent features of Btrfs is that it can spread over multiple devices, whose space is combined into a single shared pool. After that, each block of the physical storage is assigned a virtual address. These addresses, not the real ones, are then used by other FS structures. The information about the correspondence between the virtual and physical addresses is available in the Chunk B-tree. It also knows which devices form the pool. The Device B-tree, vice versa, associates the physical blocks on the underlying devices with their virtual addresses.
The File System B-tree organizes all the information about files and folders. Very small files can be stored directly in the tree inside extent items. Larger files are stored outside in contiguous areas called extents. In this case, an extent item references all extents the actual file’s data belongs to. Directory items make up the content of folders, they also include file names and point to their inode items. Inode items are used for other properties, like size, permissions, etc.
The Extent B-tree keeps track of allocated extents in extent items. It acts like a map of free space.
In the described B-trees, modifications are never performed on the spot. Instead, the modified information is written to a different location. This technique is known as Copy-on-Write.
Yet, on solid-state drives, Btrfs can detect extents that are marked as unused and wipe them automatically by launching the TRIM command.
Deletion
Procedure: Brtfs rebuilds the File System B-tree to exclude the nodes associated with the file and releases the extents allocated to it in the Extent B-tree. All the linked structures get updated.
Recovery: The necessary items are no longer a part of the FS structure. Yet, since Brtfs relies on the Copy-on-Write principle, it is possible to access the older copies, including the previous version of the File System B-tree, analyze them and successfully retrieve the deleted file, provided that its content and metadata have not been overwritten.
F2FS
F2FS is designed with the peculiarities of flash storage in mind. It splits the entire space into segments of a fixed size. A section consists of consecutive segments, and a set of sections comprises a zone.
The Superblock is found at the start of an F2FS partition. It contains the basic information about it and the location of other important areas. There is a second copy of the Superblock for backup purposes. The Checkpoint blocks store recovery points for the old and current state of crucial filesytem elements.
The placement of data is managed using special node structures. These nodes can be of three types: direct nodes, indirect nodes and inodes. A direct node keeps the address of actual data blocks, an indirect node links to blocks in other nodes and an inode contains metadata, including the file’s name, size and other properties. The mapping of nodes to their physical locations in the filesystem is stored in the Node Address Table (NIT).
The content of files and folders is stored in the Main Area. The sections in it separate the blocks that hold data from the node blocks with indexing information. The usage status of all types of blocks is indicated in the Segment Information Table (SIT) – the ones in use are labeled as valid and those that contain deleted data are considered to be invalid. The Segment Summary Area (SSA) records which blocks belong to which node.
Directory entries in F2FS are called dentries. A dentry contains the file’s name and its inode number.
F2FS performs cleaning when there are not enough free segments and in the background when the system is idle. The victim segments in this case are selected based on the number of used blocks according to the SIT or by their age.
Deletion
Procedure: The changes are made to the Node Address Table (NAT) and Segment Info Table (SIT). This information is held in memory as long a new checkpoint is created and written to the Checkpoint block. The content of released blocks remains until wiped in the process of cleaning.
Recovery: Using the recent checkpoint, it is possible to access the previous state of the filesystem metadata and locate the node and data blocks associated with the file, unless they have been overwritten.
The filesystems of BSD, Solaris, Unix
These Unix-like operating systems offer two native formats – UFS, which has been around since the early days, and the modern ZFS filesystem.
UFS
A UFS volume consists of one or more Cylinder Groups. Their locations and other important details related to the filesystem are available in the Superblock. A backup copy of the Superblock is also stored in each Cylinder Group.
Any file in UFS is composed of an inode and data blocks that have its actual content. An inode contains all the file’s properties, except its name, which is kept in a directory. It also points directly to the first 12 file’s data blocks. If the file is larger, the next address points instead to indirect blocks that contain direct block addresses.
Directories in UFS are represented by groups of entries that store a list of file names and the inode number of each file. Though a file is always associated with a single inode, in case of hard links, the same file can have multiple names. When file names in different directories point to the same inode, the number of references is indicated in the inode.
Every cylinder group keeps its own bitmaps of free blocks and free inodes. Also, there is a certain number of inodes, each containing file attributes. The rest of the cylinder group is occupied by data blocks.
Deletion
Procedure: UFS wipes the inode belonging to the file and updates the bitmaps of free blocks and free inodes. The corresponding entry is deleted from the directory.
Recovery: Without the inode, there is no information about the file’s size and first 12 data blocks. The link to its name is also permanently lost. The data can be restored using the RAW-recovery method. However, the chances are quite poor for fragmented files.
ZFS
Unlike most filesystems, ZFS can span across a series of physical drives combined into a common storage pool. A pool contains one or more virtual devices called vdevs. A vdev has a label that describes it, with four copies stored for security purposes. There is an Uberblock inside each vdev label. Similarly to the Superblock used by other FS types, it contains vital information necessary to access the entire contents.
Storage is allocated by ZFS in variable-sized units called blocks. All the blocks in ZFS are organized as objects of different types. Objects are characterized by special structures called dnodes. A dnode describes the object type, size, along with the collection of blocks that comprise its data. It can contain up to three block pointers. A block pointer is the basic structure used by ZFS for block addressing, it can point to either a leaf block that holds actual information or to an indirect block that points to another block.
The related objects are further grouped into object sets. Each object in it is uniquely identified by an object number. An example of an object set is a file system, which contains file objects and directory objects. The collection of dnodes describing the objects in the given object set are also stored as an object pointed to by the metadnode. The metadata that refers to the whole pool is also contained in an object set called the Meta Object Set (MOS).
When ZFS writes any data to the storage, the blocks are never overwritten in place. At first, it allocates a new block to a different spot. Once it completes the operation, the FS metadata is updated to point to the newly written block, while its older version is preserved as well.
Deletion
Procedure: ZFS unlinks the data blocks of the file object and the respective dnode. The object number becomes available for reuse. The file is removed from the list in the directory object. The Uberblock is replaced with a new Uberblock.
Recovery: As ZFS employs the on Copy-on-Write technique, old copies can remain in the storage pool, enabling successful recovery of deleted files. However, the data is scattered across the drives in blocks of varying sizes, therefore, the procedure cannot be accomplished without intact pool metadata, which is essential for correct reassembly of its configuration.
How TRIM impacts the chances of data recovery
Most modern SSDs and many newer SMR hard drives rely on an internal translation layer that supports the TRIM command. When enabled, TRIM allows the filesystem to inform the drive that certain blocks are no longer in use. These blocks are then marked as free and scheduled for garbage collection, a process that physically wipes the data. This approach helps to improve performance and extend the drive’s lifespan, but it also makes recovering deleted or formatted files extremely difficult, in most cases, practically impossible.
Once TRIM is executed, the drive treats the affected blocks as empty. Even if the data hasn’t yet been physically erased, all references to it are removed at the drive’s internal mapping level. As a result, the files become invisible to both the operating system and data recovery software. When garbage collection eventually runs, the data is permanently destroyed and cannot be recovered.
Garbage collection doesn’t always happen immediately. Its timing depends on the drive model, memory type and workload. It may occur within seconds, hours or even days. However, the internal mapping is updated almost instantly, and the drive will typically return zeros when reading the trimmed areas, even before the data is physically erased.
Deletion
Procedure: The filesystem marks the occupied space as available for reuse and issues a TRIM command shortly afterward. The drive updates its internal mapping to indicate that the corresponding blocks are no longer utilized and schedules them for garbage collection. The actual wiping may occur immediately or be delayed, from several seconds up to several days.
Recovery: There is usually only a very short window (often just a few seconds), during which disconnecting the drive may prevent the translator from being updated. Once TRIM has been executed, file recovery software can no longer access the data. In rare cases, data recovery professionals may still use specialized equipment that bypasses the drive’s translation layer and reads raw memory chips directly. However, success is highly uncertain and depends on many technical factors. If the drive remains powered on, garbage collection will eventually erase the data completely.
Formatting
Procedure: The file system structures are reset, and TRIM is typically issued for all blocks that were previously in use. The drive updates its internal mapping accordingly, marking these blocks as free. Garbage collection may begin immediately or be delayed, depending on the drive’s internal state and workload.
Recovery: As with file deletion, powering off the drive before garbage collection starts may leave a tiny chance for professional recovery of raw data. Once garbage collection has wiped the blocks, the data is permanently lost.
Metadata damage
Procedure: When the filesystem metadata is corrupted, the OS may no longer be able to track certain blocks, failing to issue TRIM for them. Without this command, the drive does not update the status of the affected blocks, and they are not scheduled for garbage collection.
Recovery: Since TRIM is not triggered, the data in these blocks often remains untouched, even though it is no longer accessible through the operating system. In such cases, data recovery software may be able to locate and reconstruct the lost files, though the chances depend on the extent of corruption and the file system type involved.
In closing, understanding how file systems impact data recovery is essential, but in many cases, having the right tools may also make a significant difference. To maximize the chances of success, particularly when dealing with complex or uncommon file systems, consider using professional data recovery software from SysDev Laboratories. These solutions are designed to work with diverse file systems and storage configurations, offering capabilities beyond what most basic recovery utilities can provide.